I prepared the following text as part of the process for my promotion to the rank of Full Professor at the Department of Computer Science of UFES.
1. From Childhood to Electronic Engineering at UFRJ (1974–1984)
During my childhood in Cachoeiro de Itapemirim – ES, I developed a great interest in understanding how everything around me worked (I believe this was influenced by my father's activities, as he was a watchmaker). This interest ranged from common technological artifacts, such as fluorescent lamps, to natural systems, such as the Sun (how could it generate so much energy, continuously, so stably and for so long?). Due to this interest, I became an avid reader and, thanks to Tecnirama: Encyclopedia of Science and Technology (Figure 1), I learned a great deal about almost everything that interested me at the time.

However, due to its broad scope, certain topics in Tecnirama were covered with insufficient depth to satisfy my interest. I highlight my interest in how the radio worked. How was it possible for sound generated in some distant place to reach my home through that device? Studying Tecnirama, I learned about various pieces of equipment involved in the process, such as microphones, loudspeakers, turntables, among others. But the vacuum tube radio (at the time, the active elements of radios were thermionic valves, Figure 2) was far too complex to be covered in Tecnirama with the depth I desired – I needed to learn more than what was available in it.

By chance, at 11 years of age (1974), I discovered the Instituto Rádio Técnico Monitor (now Instituto Monitor - http://www.institutomonitor.com.br), which at the time offered a technical course in "Radio, Television and Electronics" by correspondence (this teaching modality is now recognized as Distance Learning). When I turned 12 (1975), my father gave me the gift of funding this course (he passed away in a car accident before I completed the course) and, at 13 years of age, I already knew how radios, televisions, and various other electronic equipment worked (the quality of the course was excellent). Thanks to what I learned, I started working as an electronics technician in a large repair shop in Cachoeiro at age 14.
However, I soon discovered that I had learned how equipment worked, but not how to design them. This discovery came when I tried to design and build a radio transmitter, still at age 14. I succeeded, and my 5-Watt transmitter, based on the 50C5 vacuum tube (Figure 3), was capable of transmitting in AM (Amplitude Modulation), in the medium wave band (https://pt.wikipedia.org/wiki/R%C3%A1dio_AM 1 MHz), to a distance of about 200 meters – the distance from my house to the central square of the neighborhood where I lived.
To extend the range of the transmitter and reach the entire neighborhood, I built a 60-Watt amplifier for the transmitter, based on 2 6L6 vacuum tubes in a Class AB1 push-pull configuration (Figure 4). However, although I had more than tenfold increased the transmitter's power, the range did not exceed 200 meters.
Through the process of developing the amplifier and observing the results achieved with it, I realized that, although I knew how each part of the system worked, I did not know precisely how to design a radio frequency transmitter system – I had managed to design and build the transmitter and the amplifier, but I could not explain why the range had not increased. In other words, there was more to learn about electronics than what I had learned in my Radio, Television and Electronics course: how to design electronic equipment.


During this period, I also had my first contact with computing, through the magazine Nova Eletrônica, which in its first issue presented the first chapter of a Microcomputer Programming course (Nova Eletrônica no. 1, February 1977, Figure 5(a)). Due to the quality of its technical content, I began purchasing this magazine every month (it was monthly) and followed it until its last issue (no. 114, August 1986, Figure 5(b)).


Figure 5: First (a) and last (b) issues of the monthly magazine Nova Eletrônica
At 16 years of age (1979), I met in Vitória – ES an engineer with a degree in electronic engineering. He was my instructor in a course about a new color TV set from the electronics manufacturer Sharp, which was arriving on the Brazilian market (Sharp and the repair shop where I worked in Cachoeiro funded my participation in the course). During the course breaks, I was able to discuss with him the difficulties I had with my transmitter, developed years earlier. Through him, I learned what was taught in an electronic engineering program (calculus, physics, advanced electronic devices, digital electronics, etc.) and decided to become an engineer.
Still at age 16, I moved to the State of Rio de Janeiro to prepare for the university entrance exam (there was no, and still is no, electronic engineering program at UFES). I got a job as a technician at an electronics repair shop in Niterói – RJ and, at 18, I passed the entrance exam for the Telecommunications Engineering program at UFF. However, after one week of classes, I concluded that it was impossible to pursue an engineering degree as I intended and work at the same time. Thus, I decided to save enough money to go 5 years without working and, in this way, be able to dedicate myself full-time to the engineering program.
To obtain the resources necessary to go 5 years without working within a reasonable timeframe, I opened, together with a friend, a repair shop for naval electronic equipment, still at age 18 (it was necessary to officially emancipate myself to be a partner in the shop, since only those over 21 could be business owners at the time – Figure 6). Thanks to the high cost of the naval electronic equipment I repaired (Radars, Radio Direction Finders, Echo Sounders, etc.), in less than two years I had already amassed enough resources to complete my entire engineering degree without needing to work. However, my partner requested that I remain at the company for one more year for the benefit of the company and its team.

At that time, through the magazine Nova Eletrônica, I learned about the Z80 processor (Nova Eletrônica no. 42, August 1980, Figure 7(a)) and, later, through it I acquired my first computer – the NE-Z80 – which was based on this processor (no. 56, October 1981, Figure 7(b)). The NE-Z80 was sold as a component kit to assemble (http://www.mci.org.br/micro/prologica/nez80.html), meaning I assembled my first computer at age 18.


Figure 7: Covers of Nova Eletrônica magazine issues 42 (a) and 56 (b)
2. Electronic Engineering at UFRJ (1984–1988)
At 21 years of age (1984), I sold my share in the company, invested the proceeds in the financial market, and finally entered UFRJ to take the basic cycle of engineering courses (at the time, at UFRJ all engineering programs had a common basic cycle).
During the two years of UFRJ's engineering basic cycle, there were no electronics courses. Eager to learn electronics, I decided to visit the COPPE laboratories in search of learning opportunities. In this process, I met Professors Felipe Maia Galvão França (http://lattes.cnpq.br/1097952760431187, at the time a master's student) and Edil Severiano Tavares Fernandes (http://lattes.cnpq.br/4514999019313866, who passed away in October 2012), both from the Systems and Computer Engineering Program at COPPE. Felipe would become my final project advisor, and Edil, my Scientific Initiation advisor for several years and my master's thesis advisor.
Edil and Felipe granted me full access to the resources of the COPPE Systems and Computing Laboratory and encouraged my involvement in various research projects under development in the laboratory at the time. One of these projects consisted of transforming a Mitra-15 minicomputer from its original form, i.e., a microprogrammed machine (http://www.feb-patrimoine.com/english/mitra.htm), into a microprogrammable machine. This project resulted in my first national publication[1] and my second international journal publication[2]. Thanks to this and other work, while still an undergraduate, I was hired as a technician (programmer) by COPPE/UFRJ (in 1986).
My first international journal publication was the result of my final project work[3]. Titled "The Hardware of a Hybrid Parallel Machine," this work involved the design and implementation of the MPH (Máquina Paralela Híbrida – Hybrid Parallel Machine), perhaps the first Brazilian parallel computer. The MPH was a multiprocessor system organized according to a hypercubic topology and employed an interprocessor communication mechanism based on shared memory – each of its 16 nodes had four memory regions shared with four neighbors, enabling the implementation of a degree-4 hypercube (https://en.wikipedia.org/wiki/Tesseract). The processors used were 6809s (used at the time in the TRS-80 microcomputer https://en.wikipedia.org/wiki/TRS-80_Color_Computer). This project also resulted in my second national publication[4] and in the first-place award at the VII Scientific Initiation Works Competition (CTIC) of the Brazilian Computer Society (SBC), Figure 8.

With the knowledge acquired in the Electronic Engineering program at UFRJ, I learned to design not only analog electronic equipment, such as amplifiers, power supplies, and radio equipment, but also digital electronic systems such as the MPH. But something that made me particularly happy about what I learned during the program was discovering why my 60-Watt AM transmitter had not achieved a range greater than 200 meters.
Near the end of the program, I had the opportunity to build a 30-Watt FM transmitter (Figure 9). By then, I had already learned that, to be properly propagated, radio signals require an antenna: (i) of the correct size for the transmitter's operating frequency, (ii) of the correct impedance for the transmission line used, and (iii) of the correct type for the desired radiation pattern. In the case of my FM transmitter, the operating frequency was 100 MHz and the desired radiation pattern was omnidirectional. For omnidirectional transmission at this frequency, a vertical half-wave dipole antenna can be used (https://en.wikipedia.org/wiki/Dipole_antenna), which can be adjusted to have an impedance of approximately 50 Ohms (http://coral.ufsm.br/gpscom/professores/andrei/Semfio/cap6tulo%204.pdf), enabling the use of 50-Ohm coaxial cables (widely available and low-cost both now and at the time) as the transmission line. The wavelength at this frequency is 3 meters; therefore, a vertical half-wave dipole for this frequency is 1.5 meters long – something easy to build. In fact, my 30-Watt FM transmitter connected to a 1.5-meter dipole transmitted over a distance of more than 10 km with good signal quality (from Block H of the UFRJ Technology Center to Candelária, in downtown Rio de Janeiro). To achieve the same with my AM transmitter, a 150-meter dipole would have been required (the wavelength at 1 MHz is 300 meters)!
I completed my Electronic Engineering degree at UFRJ in August 1988, one semester ahead of schedule (I completed the program in 4.5 years). Thanks to my performance in the program, I received the Academic Distinction cum laude (with honors) from UFRJ.




Figure 9: (a) From left to right: oscillator module, FM modulator and Radio Frequency (RF) pre-amplifier; Standing Wave Ratio (SWR – https://pt.wikipedia.org/wiki/Rela%C3%A7%C3%A3o_de_ondas_estacion%C3%A1rias) meter module, necessary to calibrate the antenna size according to the transmitter's operating frequency and the impedance of the transmission line carrying the RF signal to the antenna, thus optimizing the amount of transmitted energy; RF power amplifier module. (b) Internal view of the oscillator module, FM modulator and RF pre-amplifier. (c) Internal view of the SWR meter. (d) Internal view of the RF power amplifier. Recent photographs.
3. Master's Degree at COPPE/UFRJ (1989–1992)
As soon as I completed my undergraduate degree, in 1988, I was promoted to researcher by COPPE/UFRJ and, in 1989, I began my master's program under the supervision of Professor Edil S. T. Fernandes. In parallel with my master's studies, I worked at COPPE as one of the designers of Brazil's first parallel supercomputer, the NCP-I[5]. The NCP-I project was coordinated by COPPE Systems Professor Claudio Luis de Amorim and funded by FINEP.

By 1990, the electronic design of the NCP-I was completed and some of its nodes were already assembled and in operation (Figure 10). I had already written a good portion of my master's thesis, had been accepted for doctoral studies at 7 universities in the United Kingdom (positively influenced by Professors Edil and Felipe, I had decided to pursue my doctorate in the United Kingdom), and had my scholarship applications for doctoral studies abroad approved by both CNPq and CAPES. However, with President Collor's rise to power, a large part of the NCP-I project's funding was cut. The manner in which the cuts occurred and the general situation of the country under Collor's presidency led me to believe that the future of scientific research in Brazil was permanently compromised. Faced with this scenario, I decided to abandon the academic career and move to Vitória – ES, where I founded a new electronics repair shop: Rock's Eletrônica (Figure 11).

Rock's Eletrônica was a great success and, within two years of operation, already had 2 branches (in the cities of Vila Velha and Linhares). However, I did not lose contact with the friends I had made at COPPE. One of them, Professor Francisco Negreiros Gomes, who was a professor at UFES and was pursuing his doctorate at COPPE during the period when I was an undergraduate, insisted that I finish my master's degree and apply for a position at UFES every time we met. In early 1993, I took his advice (Collor had already been impeached), and I completed and defended my master's thesis.
In my master's research, I investigated the instruction-level parallelism (Instruction-Level Parallelism – ILP) available in real benchmark programs of the time that could be exploited by machines with very long instruction words (Very Long Instruction Word – VLIW machines). Additionally, I investigated how VLIW machines should be balanced (the appropriate number of functional units, registers, memory access ports, etc.) to take advantage of this ILP[6],[7].
Having completed my master's degree, I applied for a professorial position at the Department of Computer Science of UFES.
4. Early Career at UFES and Doctoral Studies (1993–1999)
On September 2, 1993, I assumed the position of Professor at the Department of Informatics (DI) of UFES and stepped away from the management of Rock's Eletrônica. At the beginning of 1994, I was appointed as the DI representative in the Collegiate of the Computer Engineering Program at UFES and was elected program coordinator.
Created in 1990, the Computer Engineering Program had not yet graduated its first class and, at the time, there were doubts at CREA-ES about how the graduates would be registered there, since Computer Engineering programs were a novelty in the country. Due to this issue, I studied what the profile of a Computer Engineer appropriate for the time should be and brought the knowledge about what I learned [8] to CREA-ES. This proximity with CREA-ES led the Technology Center of UFES, which houses the Department of Informatics and all the engineering departments of the university's main campus, to nominate me as UFES's representative on the CREA-ES Council in 1995. My involvement at CREA-ES, not only in defending the Computer Engineering field but also in debating various relevant issues for the engineering field in Espírito Santo at the time, resulted in an invitation to join the board of the organization as its First Secretary Director, Member of the Budget and Procurement Committee, and Member of the Informatics Committee.
5. The Doctoral Period at University College London (1996–1999)
At the end of 1995 and beginning of 1996, I left the Board of CREA-ES and the Coordination of the Computer Engineering Program to prepare for my doctoral studies. Once again, I was accepted for doctoral studies at several universities in the United Kingdom and had my applications for doctoral fellowships abroad accepted by both CNPq and CAPES. I chose to pursue my doctorate at University College London (UCL) with a CAPES fellowship and began the program in September 1996. Before going to the United Kingdom, I sold all my shares in Rock's Eletrônica and its branches.
During my doctorate at UCL, I studied the dominant microarchitecture of processors at the time, i.e., the Superscalar architecture, and, in particular, the difficulties associated with exploiting ILP in these architectures. The main difficulty was the complexity of Superscalar machines, which grows exponentially with only a linear increase in ILP exploitation capability.
In Superscalar machines, instructions are continuously fetched from the instruction cache and placed in an instruction window where, at each machine cycle, several of them are analyzed (to identify which can be executed in parallel), selected, and dispatched for parallel execution dynamically. Dynamic instruction scheduling hardware is used to perform the analysis, selection, and dispatch of instructions for execution. The complexity of this hardware grows exponentially with the size of the instruction window because, during the dynamic scheduling process, each additional instruction accommodated in the window needs to be compared with all other instructions in the window and all instructions currently in execution.
Influenced by what I had learned about VLIW architectures during my master's studies, after my initial studies on Superscalar architectures I began to reflect on architectural alternatives for ILP exploitation based on the VLIW concept.
The main disadvantage of VLIW machines is the code incompatibility between different generations of the same architecture (lack of backward code compatibility), resulting from the static scheduling of VLIW instructions performed by the compiler for a specific VLIW hardware. My doctoral thesis was the proposal of the Dynamically Trace Scheduled VLIW (DTSVLIW) architecture [9], [10], which solves the backward code compatibility problem of VLIW machines.
5.1. The DTSVLIW Architecture
Figure 12 shows a block diagram of the DTSVLIW architecture. In a DTSVLIW processor, the Scheduler Engine fetches instructions from the Instruction Cache and executes them for the first time using a simple pipelined processor — the Primary Processor. Furthermore, its Scheduler Unit dynamically schedules the instruction sequence (trace) produced during execution on the Primary Processor into VLIW instructions, groups these VLIW instructions into blocks, and saves these blocks in the VLIW Cache. If the same code is executed again, it is fetched from the VLIW Cache by the VLIW Engine and executed in VLIW parallel mode. Although the code must initially be executed sequentially, experiments showed that a DTSVLIW machine parameterized according to the technology available in 2003 spends more than 95% of cycles executing parallel VLIW code [11].
In 1999, Professor Francisco Negreiros passed away in a car accident. The event led me to reflect on the plans we had made together for the Department of Informatics and the Graduate Program in Informatics at UFES. With my thesis already defined and the sense of urgency brought by such reflections, I decided to complete my doctorate in 3 years instead of the originally planned 4, and return to Brazil.

6. Return to Brazil — University Administration (1999–2013)
My doctoral period abroad and my debates with Professor Francisco Negreiros made me clearly see the precarious conditions for conducting research activities at the Department of Informatics of UFES in 1999. The DI (i) did not have sufficient physical space for research activities (especially laboratory space), (ii) did not have adequate hardware for research, and (iii) did not have the bibliographic resources to keep up with the state of the art in the department's areas of interest (or any other area).
My involvement in proposing and organizing debates within the department to address these problems led to my election as Head of the DI in January 2000. As Head, I began working with the Departmental Council of the Technology Center (CT) of UFES to show the other department heads and the Center's administration the needs of the DI. The DI had particularities as it had been the last department created in the Center; especially because it was created partly by a group of professors from another Center (professors from the Department of Mathematics of the Center for Exact Sciences), and partly by a group of professors from the CT. However, many of the difficulties faced by the DI were also faced by other departments in the CT. My involvement in debates about how to best address these difficulties led to my candidacy as Vice-Director of the CT in the year 2000 election for the CT's leadership. Still in 2000, I was elected Vice-Director of the CT.
As Vice-Director, I actively participated in various debates and actions that led to the improvement of conditions for teaching, research, and extension activities at the DI in particular and the CT in general. I highlight my work in coordinating the CT Physical Space Committee and coordinating the Committee for the Creation of the CT Branch Library. Thanks to the work of the Physical Space Committee, guidelines were established and actions were taken that resulted in a significant expansion of the CT's physical space, with the construction of the CT-IX building (designated for the DI) and, subsequently, the CT-X (Production Engineering) and CT-XII (available to all CT programs) buildings, among others. Thanks to the work of the Committee for the Creation of the CT Branch Library, the Technology Branch Library was created and today houses a collection of specific interest to the CT, particularly the CT's Graduate Programs.
My role as Vice-Director of the CT led to my nomination and subsequent appointment by the UFES Rector to the position of Superintendent Director of the UFES Institute of Technology (ITUFES) in June 2001 (a position I held concurrently with the Vice-Director position of the CT until September 2002). As Superintendent Director of ITUFES, I worked to ensure its continued existence, which was threatened, and to strengthen it. I also worked to strengthen the Espírito Santo Foundation for Technology (FEST), where I served as Vice-President of the Board of Directors and where I continue to serve as a member of the Board of Directors to this day. ITUFES and FEST play an important role today for the CT, UFES, and society at large in their areas of activity.
In August 2003, I was appointed to the position of Pro-Rector for Planning and Institutional Development at UFES and left the Vice-Directorship of the CT. With the election of a new Rector at the end of 2003, I left the Pro-Rector position in January 2004. During this period as Pro-Rector for Planning and Institutional Development, I coordinated the initial implementation process of the Pro-Rectorate for Planning and Institutional Development (PROPLAN). PROPLAN did not exist before this period; it was (re)created and I assumed the role as its first Pro-Rector, having carried out activities to coordinate the adaptation of its initial provisional operating location and the development of its first work plan.
In September 2004, I was reappointed by the new UFES Rector to the position of Pro-Rector for Planning and Institutional Development and remained Pro-Rector until January 2008. During this period as Pro-Rector for Planning and Institutional Development, I led the process of establishing PROPLAN at its current operating location. I coordinated the formation of its administrative staff and the drafting of the ordinances that structured it institutionally. Having given PROPLAN the form it retains to this day, I initiated the process of defining guidelines for carrying out strategic planning at UFES and subsequently coordinated the execution of the university's first Strategic Plan [12]. After the planning cycle was completed, I coordinated the implementation of the University's strategic management mechanisms, based on monitoring the planned actions. I worked, in accordance with the 2005–2010 Strategic Plan, on the Expansion of UFES's Interiorization and on coordinating the preparation of UFES's REUNI Project.
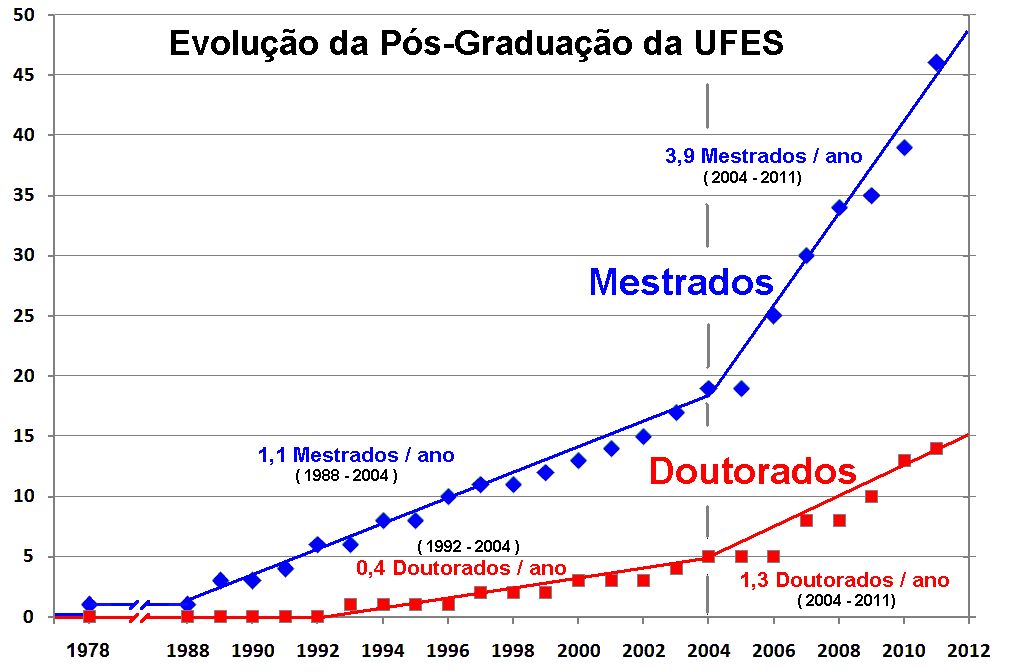
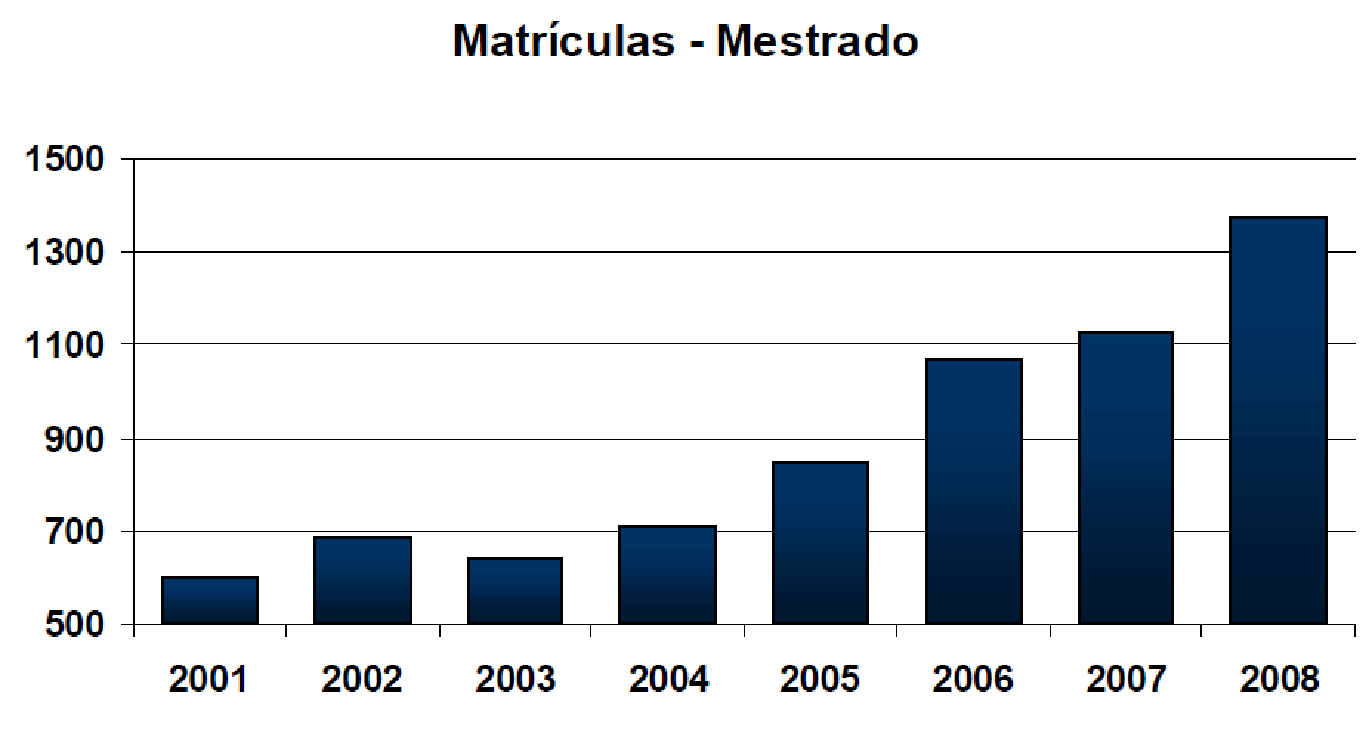
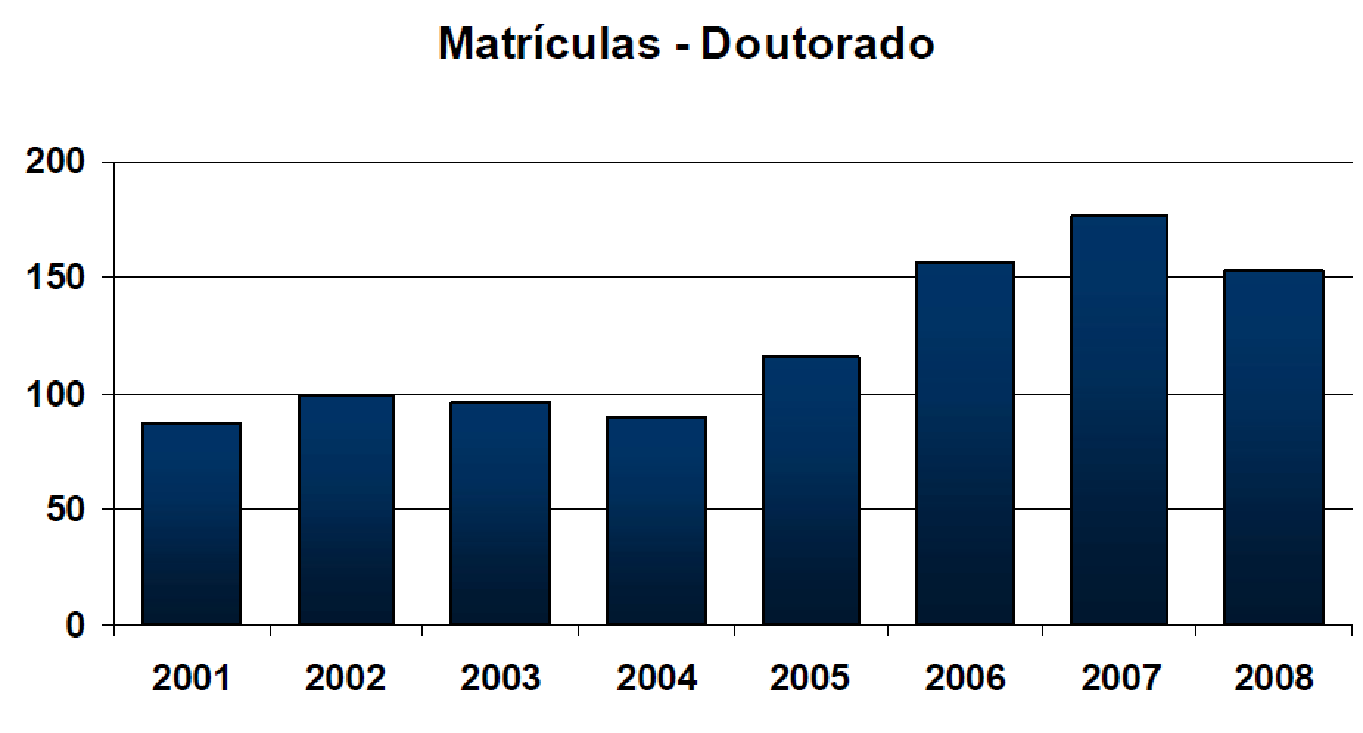
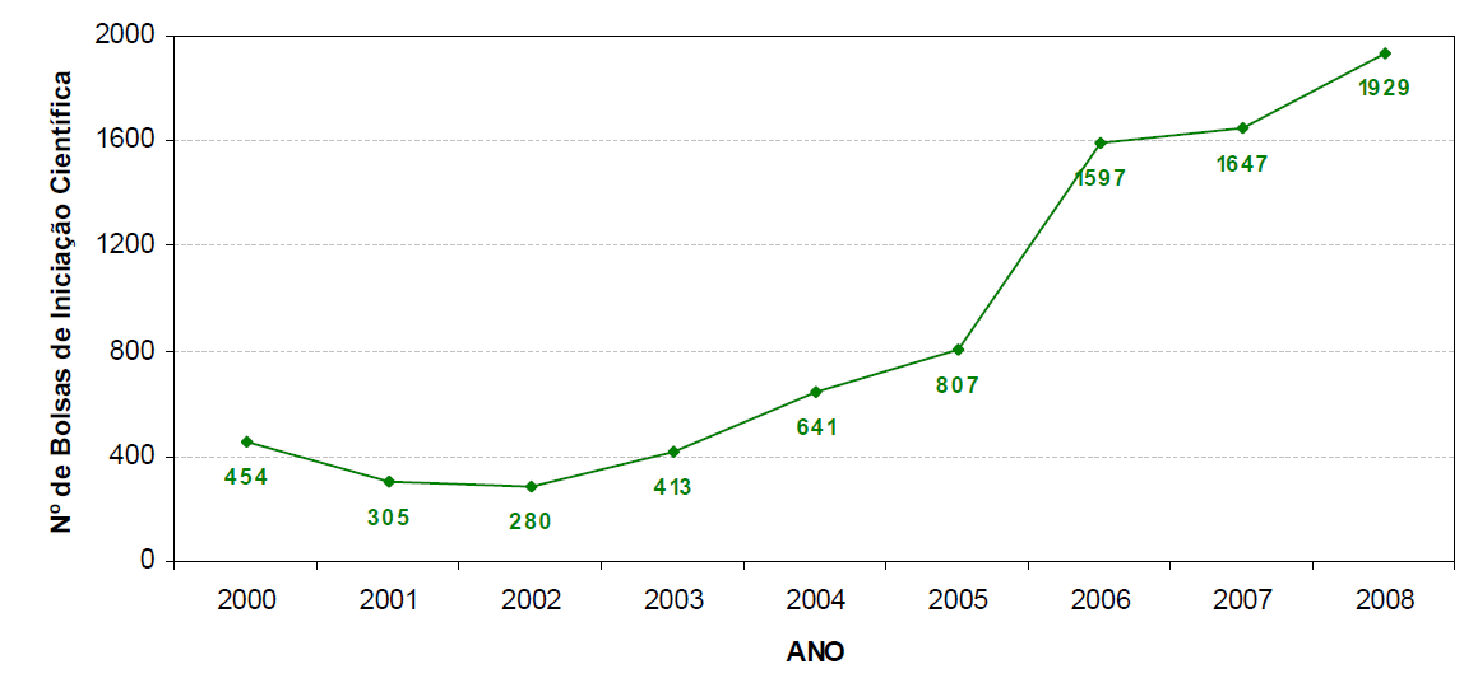
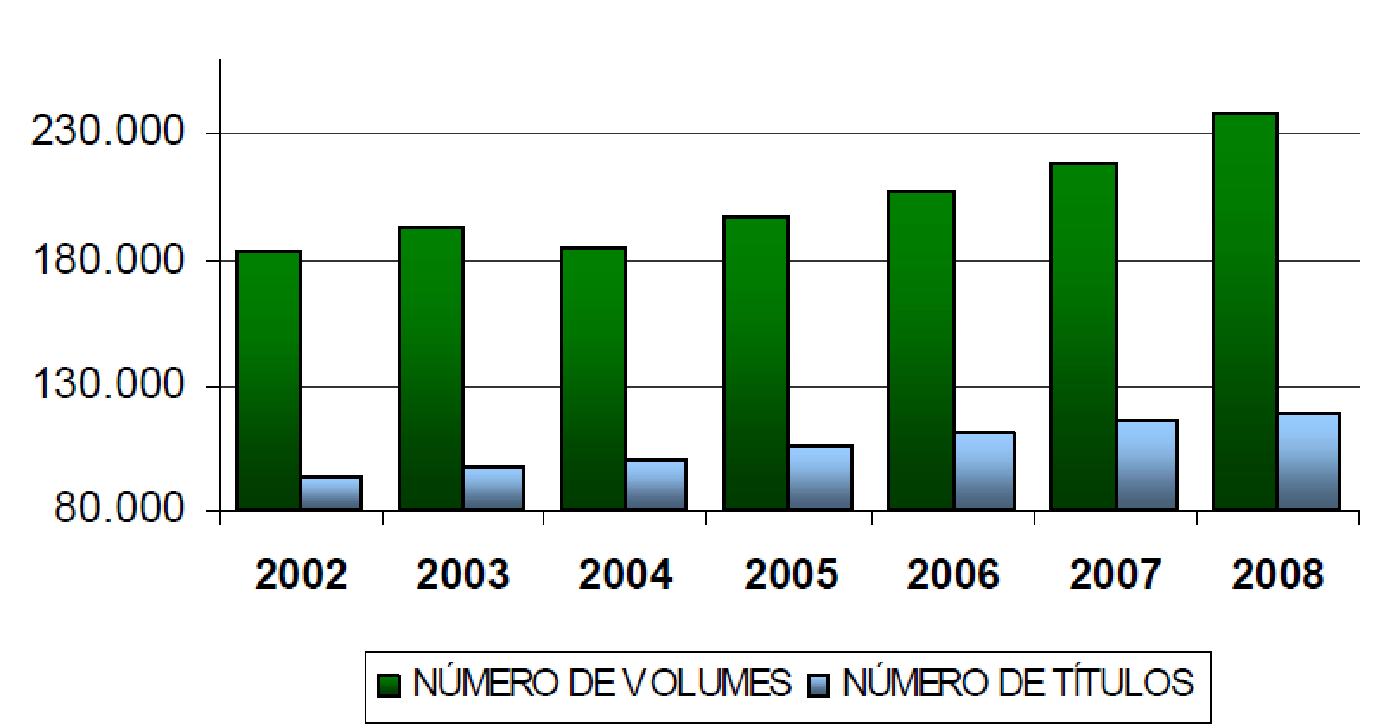
Our work leading PROPLAN, in partnership with the other Pro-Rectors and with the support of the Rectorate, contributed to the realization of most of what was planned during my tenure as Pro-Rector. Among the various achievements foreseen in the plan and accomplished by the institution, I highlight the evolution of graduate studies at UFES, with a visible change in the rate of increase in the number of master's and doctoral programs at UFES during the period I served as Pro-Rector (2004 to 2007, Figure 13), as well as the evolution in graduate enrollment numbers (Figure 14 and Figure 15), the number of undergraduate research fellowships (Figure 16), and the growth of the UFES library system's collection (Figure 17). It is worth highlighting the work of Professor Francisco Guilherme Emmerich, Pro-Rector for Research and Graduate Studies, in achieving these results during the period I was Pro-Rector for Planning and also in the following 4 years.
After I left PROPLAN, I dedicated myself to creating the Doctoral Program in Computer Science at UFES. As a member of the Graduate Program in Informatics (PPGI) at UFES, I proposed and was elected coordinator of the Committee to Develop a Project and Define Strategic Actions Aimed at Creating the Doctoral Program in Computer Science at UFES (CDOC) in June 2008. In April 2009, the project was completed and submitted to CAPES — at the time, PPGI still held a grade of 3 from CAPES. In August 2009, I was elected Coordinator of PPGI and, by the time I left the program's coordination in July 2011, the Doctoral Program in Computer Science had already been approved (in April 2010) and PPGI held a grade of 4 from CAPES.
In April 2012, I was appointed Director of Research at UFES, a position I held until March 2013. During the period I held the position of Director of Research, I dedicated myself to strengthening UFES's Scientific Initiation Conference and to creating PRPPG programs foreseen in UFES's Strategic Plan, such as the UFES Research Support Fund.
At the end of this period of more than 10 years in university administration (1999–2013), UFES in general and the DI in particular had advanced significantly and, today, the DI (i) has physical space for research activities, especially laboratory space, (ii) has adequate hardware for research, and (iii) has bibliographic resources to keep up with the state of the art in the department's areas of interest. I feel gratified for having contributed directly or indirectly to the achievement of these advances.
7. Return to Brazil — Research, Teaching, and Extension (1999–2015)
Throughout the entire period I was involved in UFES administration, I never ceased developing research, teaching, and extension activities. As soon as I returned from my doctorate (in 1999), however, the great challenge was the lack of appropriate infrastructure for research, especially for the main research topic I was working on at the time — processor microarchitecture.
Research in the area of processor microarchitecture demands a large amount of computational resources for simulating the microarchitectures under investigation. Due to the need for computational resources to conduct experiments, I joined other colleagues from the DI and founded a High-Performance Computing research group (originally at http://dgp.cnpq.br/dgp/espelhogrupo/5883089247558529, now at http://dgp.cnpq.br/dgp/espelhogrupo/2805153253373085). The group's efforts resulted in obtaining funding from the National Petroleum Agency to build a 65-processor cluster. The Enterprise Cluster [13] (Figure 18) was completed in 2003 and, as soon as it became operational in January 2003, it ranked 48th on the list of the world's most powerful clusters.

Also in 2003, my first CNPq Research Productivity Fellowship project, titled "Advanced Processor Architectures," was approved. From this project onward and up to the present day, my research, extension, and graduate teaching and undergraduate research activities have been guided by my CNPq Research Productivity (PQ) projects.
7.1. PQ Project 2003–2004 — Advanced Processor Architectures
In the years 2003 and 2004, we carried out research, teaching, and extension activities that enabled: (i) theoretical advances in the area of computer architecture and high-performance computing; (ii) theoretical advances in the area of artificial visual cognition; (iii) the development of technology that resulted in the implementation of a product prototype and two patents; (iv) the consolidation of our local research group, with four doctoral-level researchers, one doctoral student, and several master's and undergraduate students; and (v) the improvement of our group's research infrastructure, with the creation of a laboratory and implementation of a 65-processor cluster.
7.1.1. Theoretical Advances in Computer Architecture and High-Performance Computing
7.1.1.1. Energy Consumption and Heat Dissipation
In this research work, we experimentally analyzed the dynamic and static energy consumption of the DTSVLIW architecture [14]. Dynamic energy consumption results from the charging and discharging of capacitors formed by: (i) the interconnections between the various hardware structures existing in the processor, and (ii) the various parts of the CMOS transistors that implement these structures. Static consumption, in turn, results from the leakage current of the CMOS transistors. Nearly all the energy consumed by processors is transformed into heat, and this heat must be dissipated; otherwise, the temperature increase resulting from the failure to dissipate the heat can damage the processors. To analyze energy consumption and dissipated heat separately, we first measured the heat dissipated during the execution of test programs, in Watts, and then the energy spent per instruction, in Joules/instruction, during the execution of these programs.
To carry out the experiments, we implemented a version of our DTSVLIW simulator with consumption meters. To place the results of the study in the context of processors existing at the time of the project, we compared the energy consumption of a hypothetical implementation of the DTSVLIW architecture with hardware equivalent to the Alpha 21264 processor [15]. To evaluate the dynamic energy consumption of the Alpha 21264 processor, we used the Wattch simulator [16]; while for evaluating static consumption, we used the Hotleakage simulator [17], both publicly available. Both our DTSVLIW simulator and the Wattch and Hotleakage simulators are based on the SimpleScalar-3.0 simulator (www.simplescalar.com), which enabled an appropriate comparison between the experimental measurements of the two architectures (DTSVLIW and Superscalar).
Both simulators used (DTSVLIW and Alpha 21264) interpret executable programs produced by standard compilers that generate code for the Alpha Instruction Set Architecture (ISA). In the experiments, we used a subset of the SPEC2000 executable suite (www.specbench.org) provided with the SimpleScalar simulator. These executables were produced on an Alpha 21264 machine running the Digital UNIX V4.0F operating system, and were compiled by the DEC C V5.9-008 compiler (Rev. 1229), or by the Compaq C++ V6.2-024 compiler (Rev. 1229), or by the Compaq Fortran V5.3-915 compiler (f77 and f90). As inputs for the SPEC2000 programs, we used the input set developed at the University of Minnesota [18]. With this input set, the SPEC2000 programs selected by the researchers at that university require only a few billion instructions for their execution (approximately one second of processing on an Alpha machine of that era), but this number of instructions is sufficient to capture the processor's performance when executing these programs18.
We used four types of fabrication technology in the experiments: 70nm, 100nm, 130nm, and 180nm. However, since the results obtained for dynamic consumption and dissipation vary only by a scaling factor from one technology to another, we present here only the results for the 180nm technology (this was the technology employed in the fabrication of the 800MHz Alpha 21264). We used a supply voltage of 2V, a working frequency of 1GHz, and a CMOS transistor threshold voltage of 0.55V1414.
A strategy used to reduce energy consumption and heat dissipation in processors is conditional clocking, where functional units not used in a cycle do not receive a clock pulse. To model the conditional clocking technique, the consumption and dissipation of each hardware unit in our simulators were scaled linearly with the number of accesses to them — that is, if in a given cycle a unit is accessed, its full consumption is accounted for; otherwise, it is not. However, we added consumption equivalent to 10% of the maximum consumption of each unit when the unit is not accessed, a percentage typically used by the industry [16].
Figure 19 and Figure 20 below present graphs with the dynamic heat dissipation measured in our experiments with integer and floating point programs from SPEC2000, respectively.
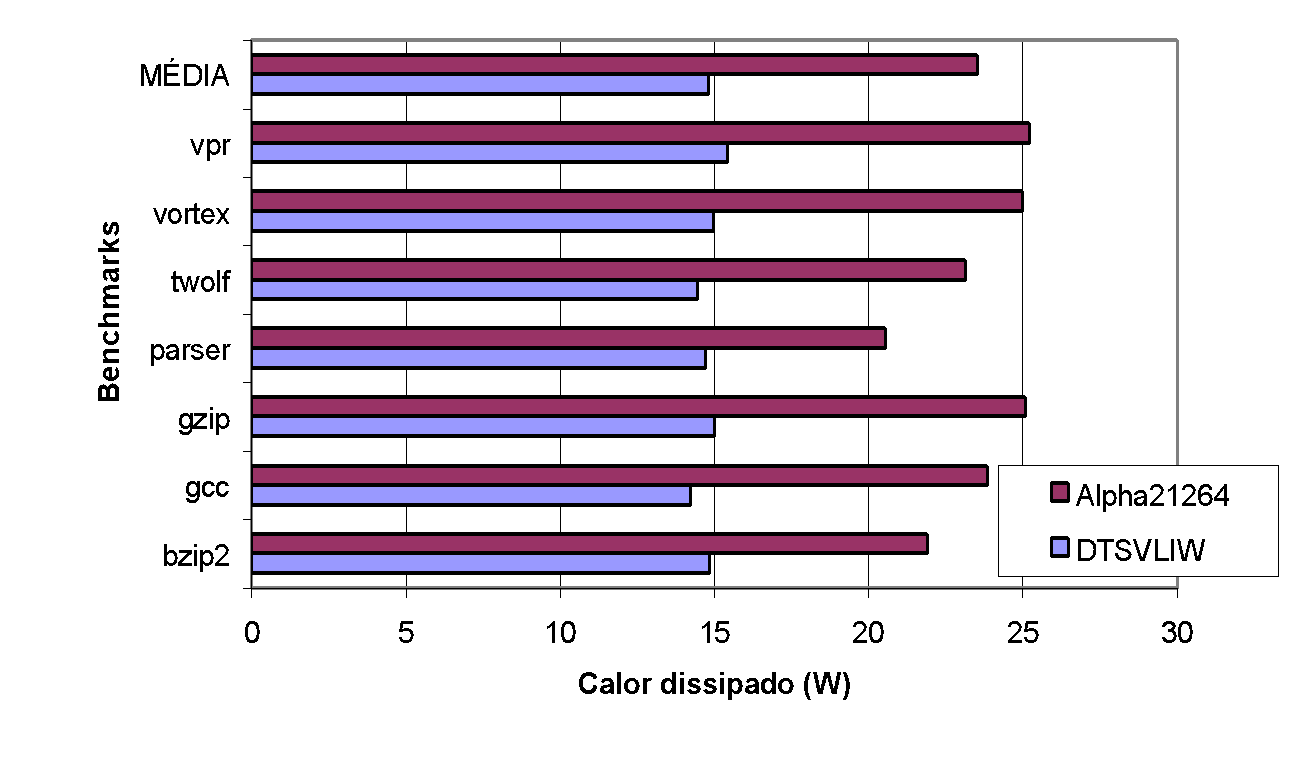
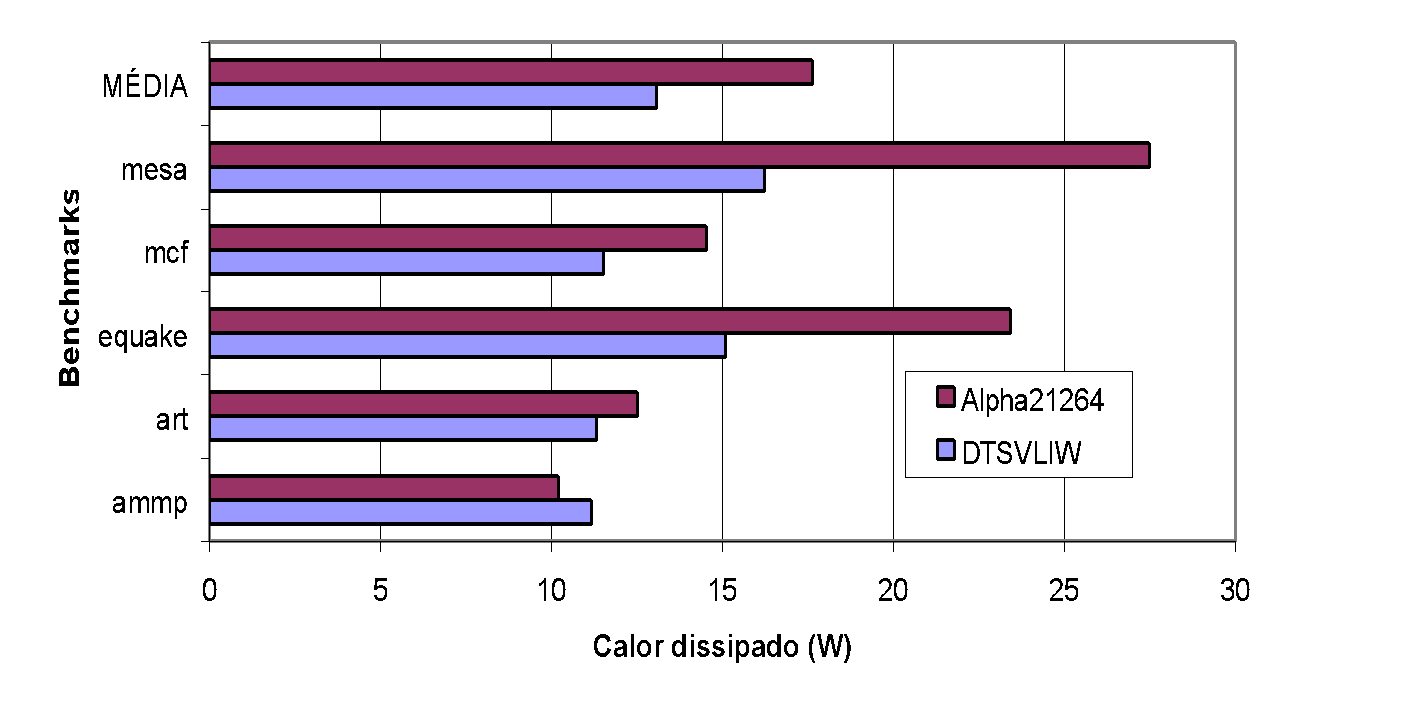
As the graphs in Figure 19 and Figure 20 show, the heat dissipated by the DTSVLIW processor is significantly lower than that dissipated by the Alpha 21264 for both integer and floating point programs. The heat dissipated by the DTSVLIW is lower than the Alpha 21264 for all integer programs, with an average of 14.80W compared to 23.54W for the Alpha 21264 — that is, 37.12% less dissipation on average. For floating point programs, the heat dissipated by the DTSVLIW is significantly lower than the Alpha 21264 for the mesa and equake programs, but this difference is less pronounced in the cases of mcf, art, and ammp, and in the case of the latter, the Alpha 21264 outperforms the DTSVLIW (we will discuss these cases further ahead). However, on average, the DTSVLIW dissipates 13.06W compared to 17.63W for the Alpha 21264 — that is, the amount of heat dissipated by the DTSVLIW in floating point programs was 25.92% lower than the amount dissipated by the Alpha 2126414.
The DTSVLIW architecture dissipates less heat because it executes programs in two modes: a scalar mode, when, in addition to executing code on the Primary Processor, its Scheduling Unit schedules and saves the code in the form of VLIW instructions; and a VLIW mode, when the VLIW instructions are executed on the VLIW Machine. The DTSVLIW executes code in VLIW mode during most clock cycles; thus, its scheduling unit does not receive clock pulses and its heat dissipation is greatly reduced in this mode. The Superscalar architecture of the Alpha 21264, on the other hand, schedules code in every cycle to extract its ILP; therefore, the scheduling hardware of this processor must receive clock pulses during virtually the entire execution. In addition to receiving clock pulses virtually all the time, the scheduling hardware must receive the results produced by the functional units and use them to enable new instructions awaiting results to be dispatched for execution. That is, the three parts of the Superscalar scheduling hardware produce the observed heat dissipation differences, namely: (i) the logic for dispatching instructions coming from the fetch stages to the reservation stations, (ii) the logic used to propagate results to the reservation stations and enable ready instructions, and (iii) the logic for issuing these ready instructions from the reservation stations to the functional units.
As can be seen in the graph of Figure 20, in the case of the mcf, art, and ammp programs, the dissipation of the DTSVLIW processor approaches that of the Alpha 21264, and in the case of the ammp program, the dissipation of the Alpha 21264 is lower than that of the DTSVLIW. To understand these results, it is necessary to examine the effect of memory hierarchy latency on the performance of these processors.
In Figure 21 and Figure 22, we present the results of experiments conducted to examine the impact of instruction and memory hierarchy latencies on the performance (in terms of instructions executed per cycle) of DTSVLIW and Superscalar processors [19]. For each horizontal bar in Figure 21 and Figure 22, the length of the first segment (from left to right) indicates the performance obtained by the machine for each program considering normal latencies, the width of the bar up to the far right of the second segment indicates what the machine's performance would be if the latency of all instructions were equal to 1, and the width of the entire bar indicates what the machine's performance would be with instruction latency equal to 1 and perfect caches.
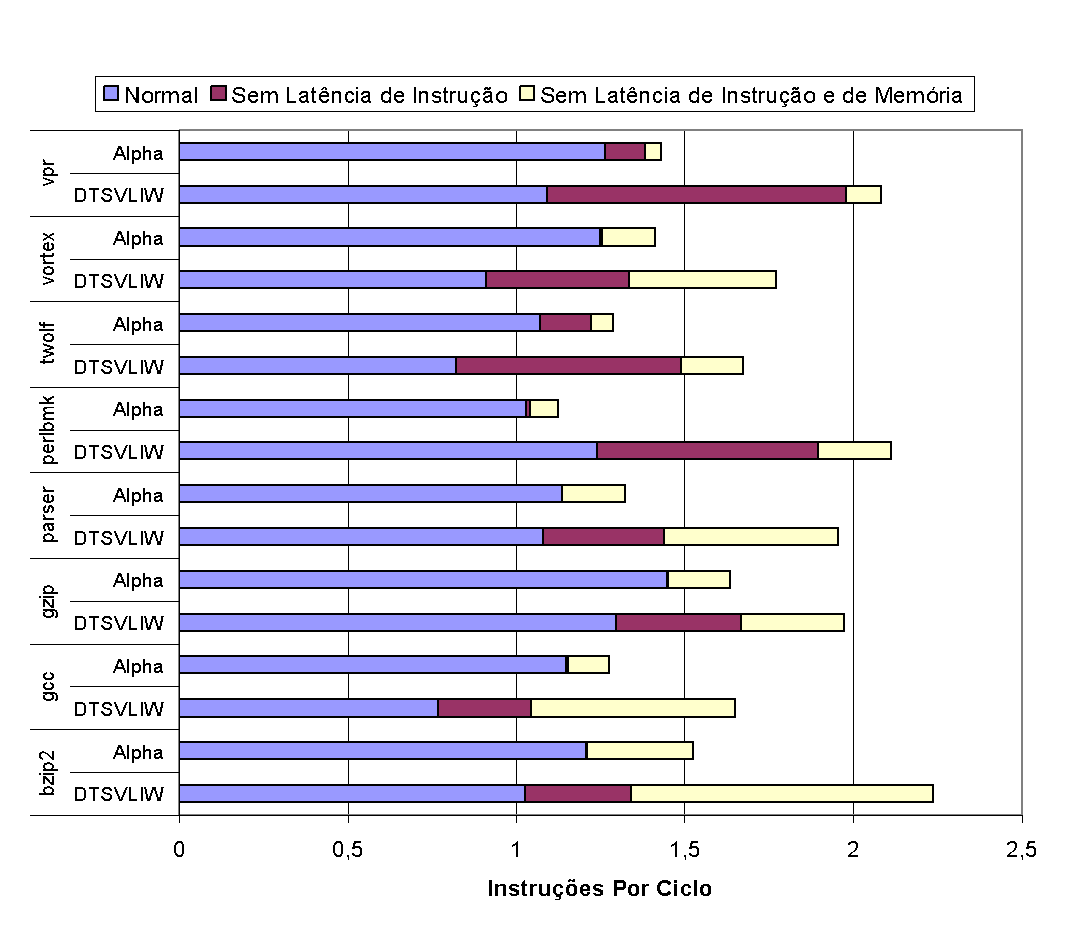
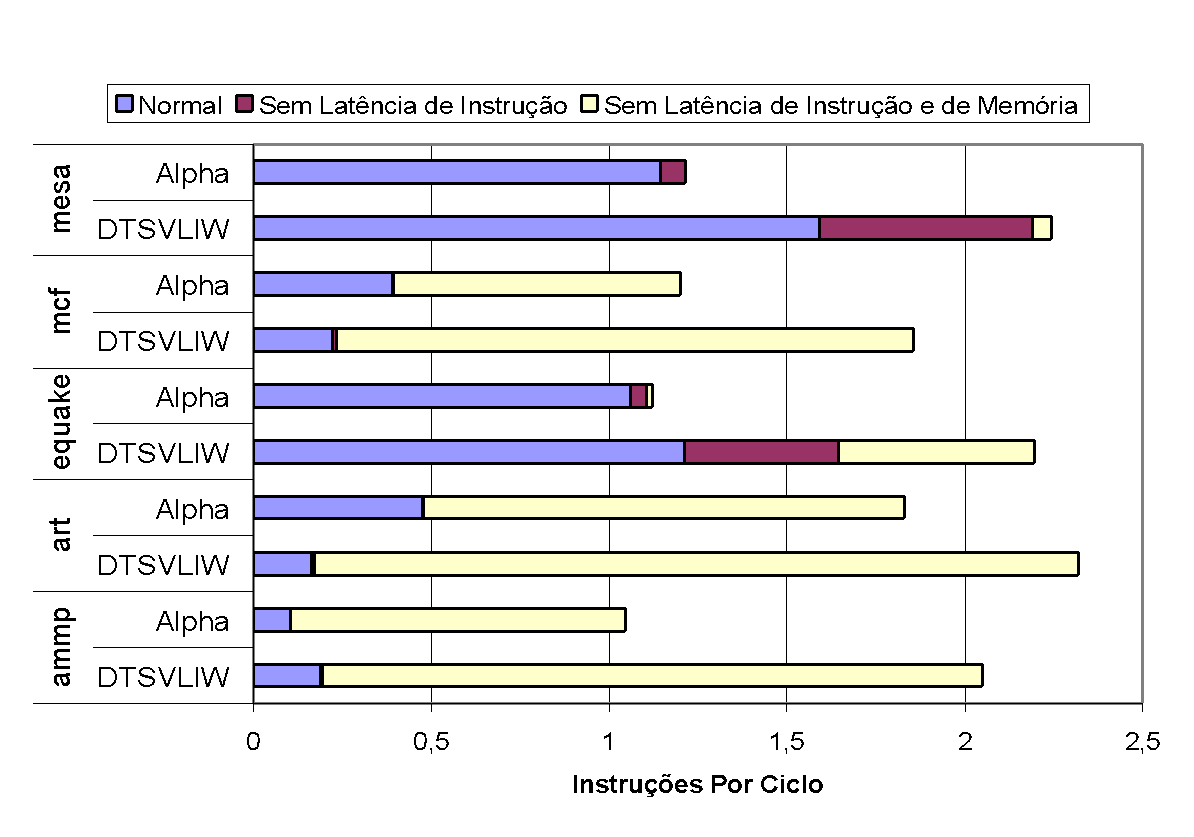
As the graphs in Figure 21 and Figure 22 show, considering all latencies, the Alpha machine has higher performance than the DTSVLIW in all integer programs except perlbmk, while the opposite occurs with floating point programs, where the DTSVLIW machine has better performance than the Alpha in all programs except art and mcf. On average (harmonic mean19), the Alpha exhibits 18.4% higher performance than the DTSVLIW for the integer programs tested and 8.3% for the floating point programs. However, it is important to note that, when instruction latencies are disregarded in both machines, the DTSVLIW surpasses the Alpha in integer programs by a wide margin and achieves the same average performance in floating point programs. That is, the Superscalar architecture demonstrated greater ability to minimize the impact of instruction latencies, which was expected. The performance measured without considering instruction and memory latencies shows the DTSVLIW architecture further ahead of the Superscalar: the DTSVLIW surpasses the Superscalar by a wide margin in all programs. This was expected, given that the DTSVLIW's Scheduling List has the capacity to accommodate more instructions than the Superscalar's issue queues19.
The heat dissipation of the DTSVLIW processor approaches that of the Alpha 21264 in the floating point programs mcf, art, and ammp because, in these programs, both processors spend most machine cycles waiting for memory accesses. Since their hardware is equivalent, their consumption when idle is practically the same.
7.1.1.2. Energy Consumption
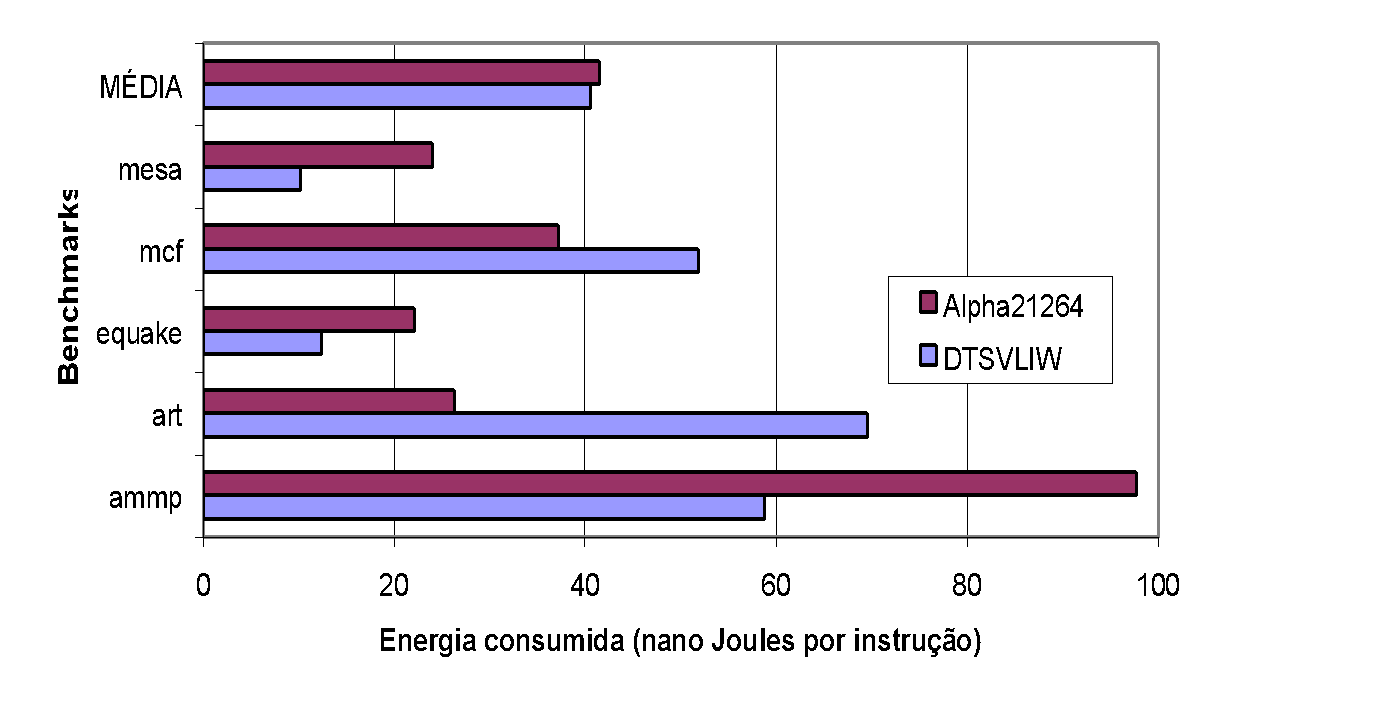
We used the energy dissipation in the form of heat presented in Figure 19 and Figure 20, together with the performance obtained in the experiments summarized in Figure 21 and Figure 22, to compute the energy consumption, in terms of Joules per instruction, of the processors under study. To do this, we divided the values in Watts (Joules/second) from Figure 19 and Figure 20 by the values in instructions per cycle from Figure 19 and Figure 20 (instructions per nanosecond, in fact, since the clock frequency used in the experiments is 1GHz), and obtained the graphs in Figure 23 and Figure 24, which show the energy consumption of each processor in nanoJoules per instruction. In the calculations, we used the length of the first segment of the graphs in Figure 19 and Figure 20.
As can be seen in the graph of Figure 23, the energy consumption per instruction executed on the DTSVLIW processor is lower than on the Alpha 21264 processor for all integer programs tested — on average 26.07% lower. For the case of floating point programs, the DTSVLIW processor consumes less energy per instruction executed than the Alpha 21264 in the mesa, equake, and ammp programs, while the Alpha 21264 processor consumes less than the DTSVLIW in mcf and art (Figure 24). The difference in energy consumption per instruction is smaller in the case of floating point programs, but still favors the DTSVLIW, which consumes on average 2.15% less energy per instruction than the Alpha 21264.
The pattern of energy consumption per instruction in floating point programs observed in the two processors is quite distinct from that observed in integer programs. While in integer programs the DTSVLIW architecture produces better results in all cases, in floating point programs the Superscalar architecture of the Alpha 21264 presents better results by a wide margin in two cases. This can also be understood by analyzing the impact of memory latency on the performance of each of these architectures.
As can be seen in the graph of Figure 22, for the mcf, art, and ammp programs, the DTSVLIW and the Alpha 21264 have their performance strongly affected by the memory hierarchy latency. Both machines spend most clock cycles waiting for data to be read from or written to memory rather than using their hardware to execute instructions. Under these circumstances, their energy consumption is mainly associated with the consumption of functional units and caches when they are not receiving clock pulses (10% of maximum consumption). But this energy is spent without performing useful work and, for this reason, the energy cost per useful instruction is high in the case of these three programs.
The analysis of heat dissipation, performance, and energy consumption of the two architectures in the case of the ammp program illustrates well the interrelationships between the variables under study. Examining the graph of Figure 20, it is possible to verify that, when executing this program (and in our experiments only this program), the DTSVLIW dissipates more heat than the Alpha. But, observing the performance of the two architectures for this program in Figure 22, we see that the DTSVLIW performance is almost double that of the Alpha. This explains why the energy consumed per instruction during DTSVLIW execution of this program is much lower than during Alpha execution, as can be verified in Figure 24.

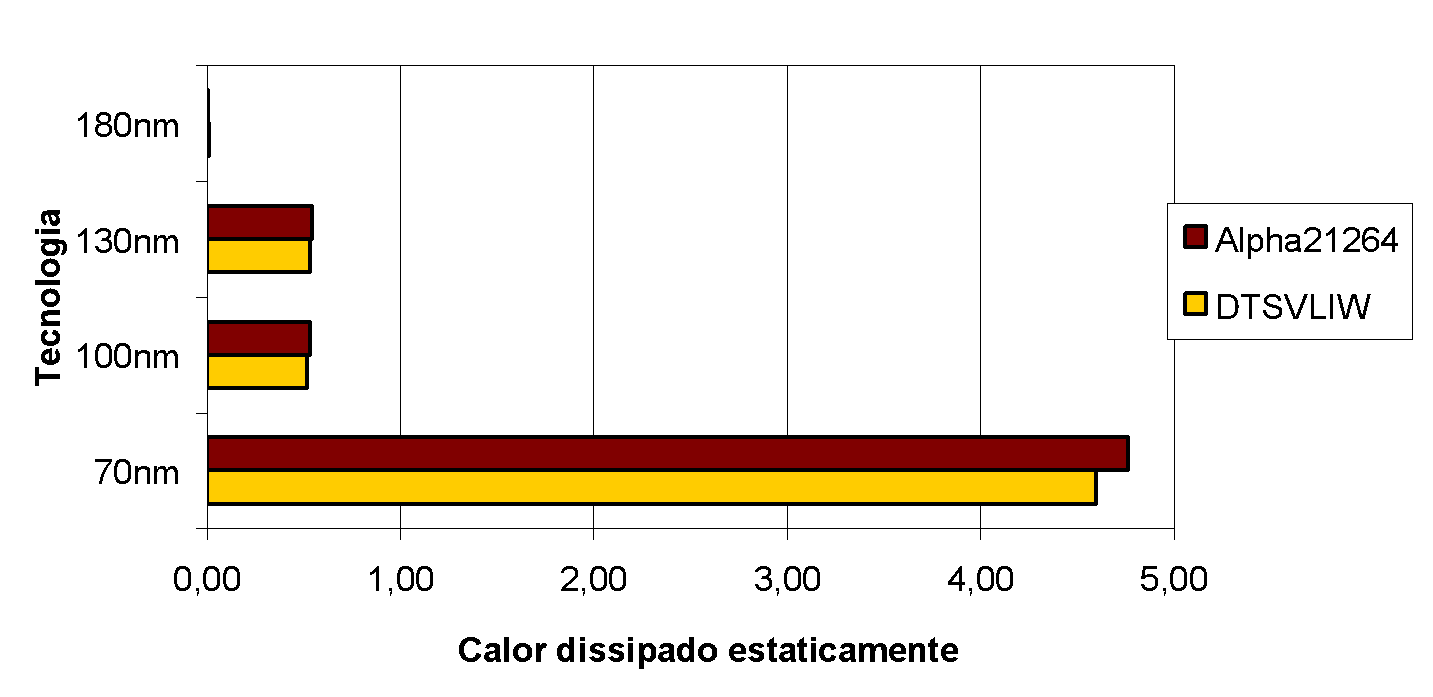
7.1.1.3. Statically Dissipated Heat
The graph in Figure 25 presents the statically dissipated heat in the two processors studied for the technologies used in the experiments. It shows that static heat dissipation is very small in both processors for an implementation with 180nm technology, but begins to become significant starting from 70nm. The amount of statically dissipated heat in the DTSVLIW and Alpha 21264 processors modeled is, however, very close, as can be seen in Figure 25, since the hardware of the two processors was made as equivalent as possible14.
In 2004, the trend for the future was for static heat dissipation to surpass dynamic dissipation [20]. However, various chip implementation techniques have been and are being studied to limit static heat dissipation, such as high-k dielectrics20 and carbon nanotube-based transistors [21], for example.
7.1.1.4. Impact of Memory Latency on DTSVLIW Performance
In Figure 21 and Figure 22, the results of a study conducted to examine the impact of instruction and memory hierarchy latencies on DTSVLIW performance were presented19. This study showed that the main advantage of the DTSVLIW architecture over the Superscalar is the simplicity and effectiveness of its instruction scheduler. It also showed that the main disadvantage of the DTSVLIW relative to the Superscalar is its limited ability to inhibit the negative effect imposed by main memory access latency on performance19. In seeking to reduce the impact of memory hierarchy latency on DTSVLIW performance, we developed a version of this architecture with multiple execution contexts implemented in hardware [22]. A machine with multiple contexts implemented in hardware, or multithreaded [23],[24], has two or more replicas of the internal structures (basically registers) responsible for storing the machine state (context). Thus, the machine can switch from executing one program to executing another very quickly. With this capability, upon detecting a cache miss that forces a main memory access, the machine could switch the running program in the hope of finding this other program in a condition to execute useful instructions.
Our results showed that the use of multiple execution contexts implemented in hardware can be an alternative to mitigate the negative effect of memory hierarchy latency on DTSVLIW performance22. Figure 26 and Figure 27 below show these results.
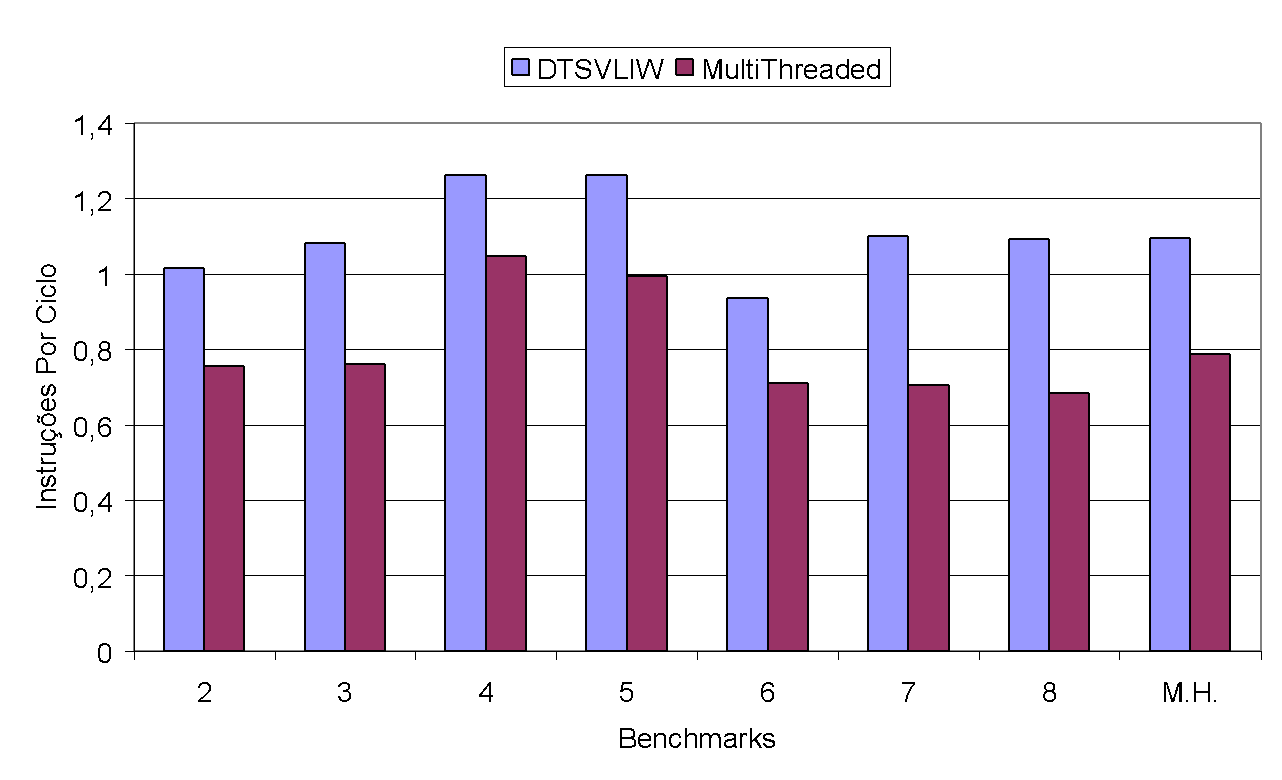
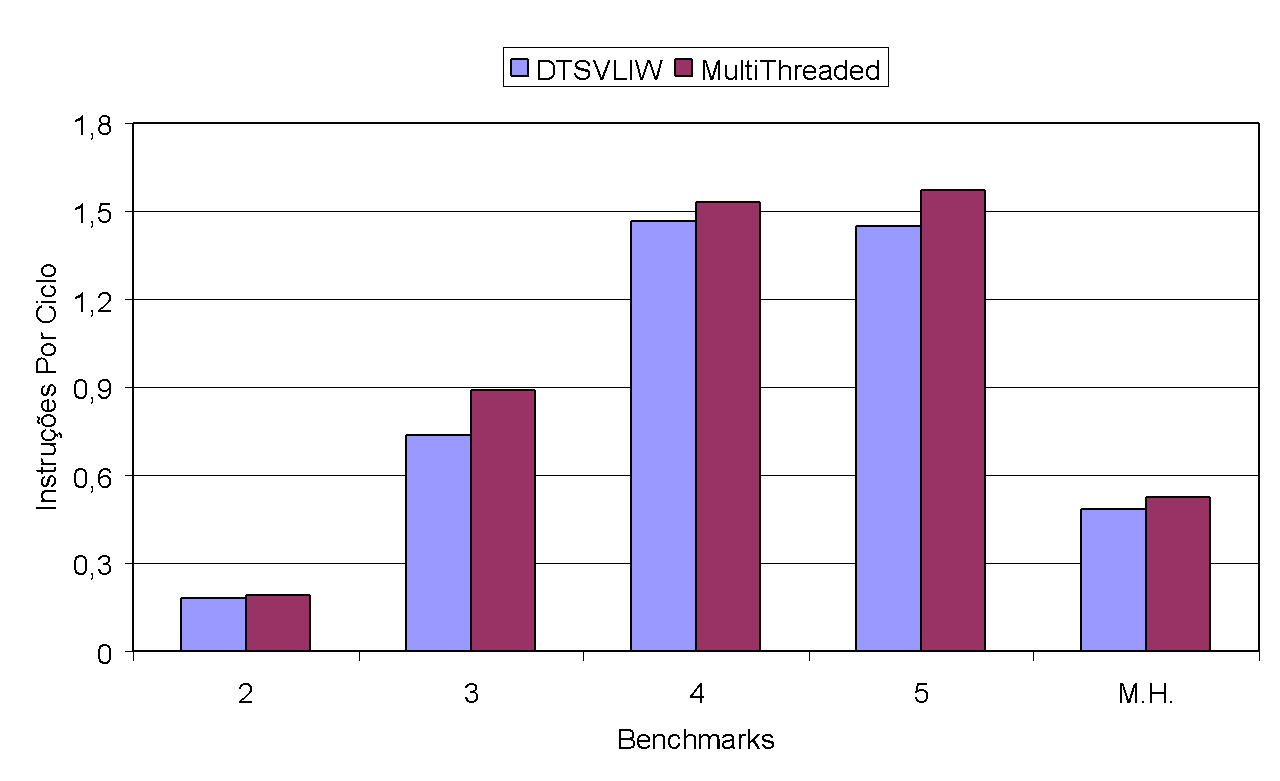
To produce the experimental results shown in Figure 26 and Figure 27, we varied the number of contexts between 2 and 8. The Multithreaded performance shown in these figures equals the sum of the number of instructions executed in each context of each experiment divided by the total number of cycles needed to execute all contexts of each experiment. The DTSVLIW performance, in turn, is the sum of the number of instructions executed by each of the programs corresponding to each context of the Multithreaded execution (executed individually up to the same point that each of them reached in the Multithreaded execution) divided by the sum of the number of cycles needed for the individual executions. The test programs used were those from SPEC2000, under conditions identical to those used in the experiments discussed previously.
As the graph in Figure 26 shows, the performance of the DTSVLIW architecture version with multiple contexts was lower than that of the version with only one context for all integer programs — a decrease of up to 37.5% (8 benchmarks). However, in the case of floating point programs (Figure 27), the performance of the DTSVLIW with multiple contexts is superior (by up to 20.5%, as in the case with 3 benchmarks) to the DTSVLIW for any number of contexts used. Upon carefully analyzing the results of the experiments conducted, we observed that, in most cases, the VLIW cache was not large enough to accommodate the number of scheduled VLIW blocks.
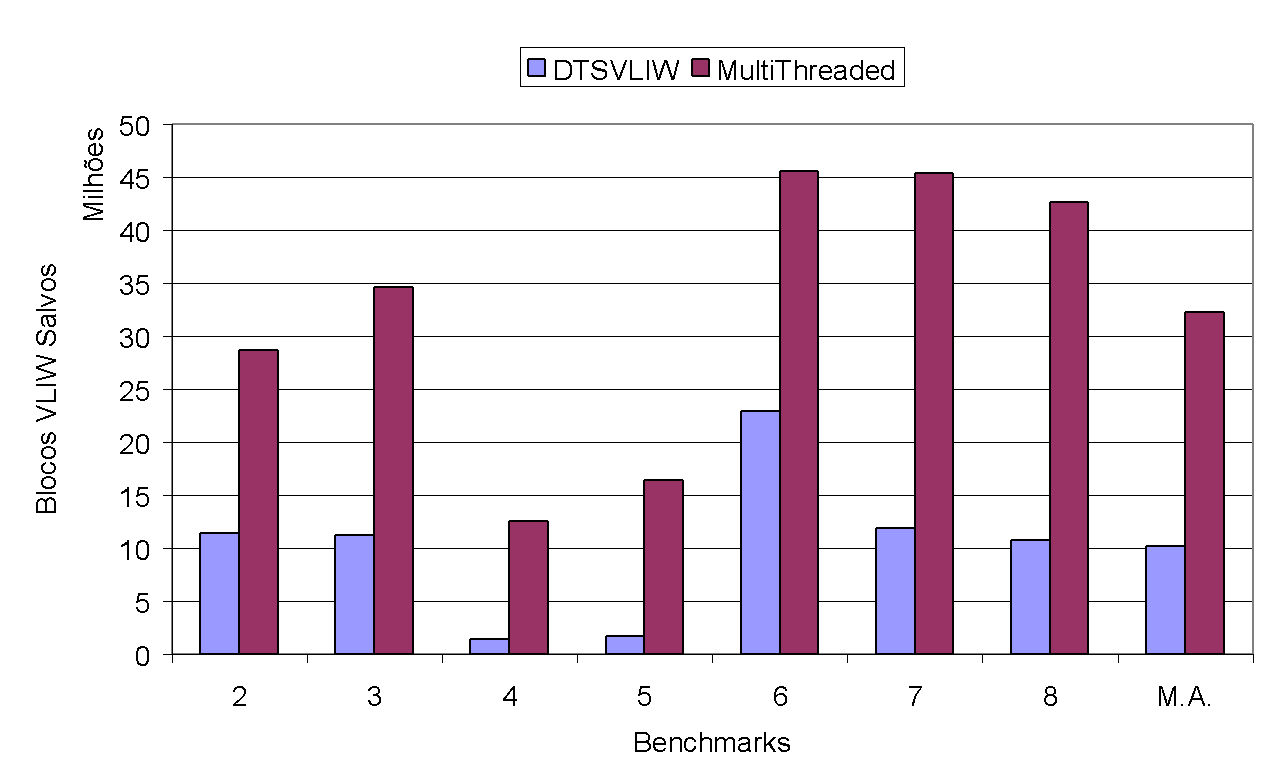
As can be seen in the graph of Figure 28, where we show the number of VLIW instruction blocks scheduled for integer programs, the DTSVLIW with multiple contexts scheduled more than triple the number of blocks compared to the DTSVLIW (in the graph, M.A. stands for arithmetic mean). The same is not observed in the case of floating point programs, as can be seen in the graph of Figure 29. Thus, it is possible to conclude that the performance difference of the DTSVLIW with multiple contexts when executing integer and floating point programs is due to the fact that integer programs, in general, repeat large code sections, which results in the scheduling of many VLIW blocks that are eventually replaced during the execution of other benchmarks subsequently, forcing the rescheduling of these blocks. On the other hand, floating point programs generally work with repetitions of small code sections that perform operations on a large data set, thus generating fewer VLIW blocks (note the order of magnitude of the graphs in Figure 28 and Figure 29) and, consequently, using less of the VLIW cache.
7.1.2. Theoretical Advances in Artificial Visual Cognition
7.1.2.1. Modeling Vergence Eye Movements
Our visual perception is egocentric, that is, centered on our position in the environment. We normally do not even notice this, but it would be terrible if visual perception were oculocentric (constructed from the eye's position relative to the environment), as the image of the world would move with eye movements. However, in an apparent paradox, the cerebral visual areas responsible for the early stages of visual perception attribute analysis have exactly this arrangement—oculocentric. Even so, when we move our eyes, we feel that the external world is stable, meaning our internal image of the external world exhibits the property of "position constancy." This is just one example of the fact that human visual cognition depends not only on physical factors (the optics of the eye) or the type of photodetector surface (the retina) of the eyes, but also on knowledge of the position of the eyes and body, and the movement of the body and head. Thus, the motor systems influence visual perception, and it is important that there be feedback from the motor systems to the visual perception system. Therefore, the oculomotor system (responsible for eye movements) plays an important role in human visual perception [25].
In this research project, we studied characteristics of the biological visual perception system and the oculomotor system. As a result, we formulated a new model for the control of the oculomotor system related to the vergence movement of the eyes toward a point in space (in three dimensions, or 3D) [26],[27],[28]. The vergence movement adjusts the position of the eyes so that the image of the same point in space is brought to both foveae (the central part of the retina).
7.1.2.2. Determining Position of a Point in Space from Vergence
The human visual system is capable of estimating the distance from the observer to a point in 3D space. Knowing this, and armed with the vergence model we developed28, we modeled a triangulation mechanism that, from a point chosen by an operator in space and the known distance between two appropriately aligned cameras, allows us to calculate the precise position of the point in 3D space. With the success of our model, we applied for and were awarded resources from the Fund for Science and Technology Support of the Municipality of Vitória (FACITEC) to develop a semi-automatic system capable of remotely measuring the volume of log piles from images captured by cameras [29]. Such a system would allow the work of measuring the wood stock of companies like Aracruz Celulose (now Fíbria), which at the time (2004) was done slowly, imprecisely, and with high risk to workers' lives—since they had to make direct contact with the wood piles to take measurements—to be done precisely, automatically, and with results available online. It is important to note, however, that once the technology was developed for this specific object of study, it could be used in other contexts. In fact, this technology was transferred to the company Mogai (www.mogai.com.br), created by former DI students, through the supervision of PPGI master's students who were Mogai employees.
7.1.2.3. Building an Internal 3D Image of the External World
From the composition of known mathematical models of the behavior of human primary visual cortex cells with models we created of the primary visual cortex architecture, we developed a system capable of building a simplified internal representation of the external world. Figure 30(a) shows a pair of computer-generated stereo images, and Figure 30(b) shows the 3D reconstruction generated by our stereoscopic vision system when we take the center of the rod as the vergence point, that is, when our system is looking directly at the center of the rod.


The plane visualized in Figure 30(b) is due to the fact that all depths impossible to compute because of the lack of information in the image (black area in Figure 30(a)) receive a depth equal to the distance to the vergence point. The observer is located at the origin of the XY plane looking upward (in the positive Z direction), so that points above the vergence plane are farther from the observer, while points below the vergence plane are closer. Note that the central point, corresponding to the vergence point, necessarily lies on the vergence plane.
7.1.2.4. Modeling the Architecture and Response of the Primary Visual Cortex
The images projected on our retinas are carried to the brain areas responsible for processing visual information through parallel visual pathways [30]. Evidence shows that each pathway is specialized in a type of information such as color, shape, and motion. At the time of this project, we were studying these pathways and formulating models to simulate the flow of visual information in the human brain. A first success of this effort was our modeling of the Retina–Primary Visual Cortex (V1) mapping [31].
Figure 31 shows the representation of the stimulus produced in cortex V1 by an image containing concentric circles. This representation was obtained by Tootell [32] through the application of radioactive 2-deoxyglucose (an organic compound that is transferred from neuron to neuron along their interconnections) in the eye of a macaque monkey and the control of the fixation of the fovea of that eye on the center of the image. After 45 minutes, the monkey was sacrificed, and the part corresponding to V1 of the left hemisphere of the monkey's brain was cut out, flattened, and placed over a radiation-sensitive photographic film that, when developed, showed the image in Figure 31.
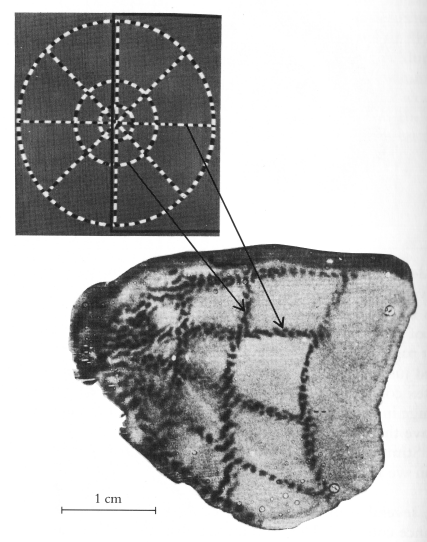
Figure 32 shows the result produced by our V1 model from an input image equivalent to the one used by Tootell. Unlike Tootell's experiment, where only one hemisphere is shown, in the image representing the output of our model, Figure 31(a), both hemispheres are shown. As can be seen in the left part of Figure 31(b), our model produces results quite close to those observed in the biological visual system.
(a)

(b)
Using our Retina–V1 mapping model and our models of V1 cells sensitive to the difference between the images captured by the left and right eyes, we were able to formulate an internal computer representation of the 3D image of the external world centered on the vergence point of the eyes. Figure 33 shows the result of applying our model in a situation where the vergence point is the mug shown in the figure.
In Figure 33(a), the images captured by the left and right cameras are shown, using a separation between cameras approximately equal to the separation between human eyes (6.5 cm). In Figure 33(b), we present the result of translating the internal computer representation (several planes of cells like the one in Figure 32(b), not shown here) back into a 3D space, from three different angles (without altering the input images, which are the same as in Figure 33(a)). As can be observed in Figure 33, the representation at the vergence point is more detailed, as in the human case (when we look at a specific point, we do not see the surrounding points sharply—try reading the word at the beginning of this paragraph while fixing your gaze on the period that ends it).


(a)



(b)
7.1.3. Technology Development
To generate parallel versions of existing programs capable of exploiting the computational capacity of clusters, or to write new parallel programs with this capability, powerful tools for analysis and debugging of parallel code are required [33]. These tools allow detecting imbalances in the distribution of the computational load among the various computers in the cluster, in addition to indicating how time is being distributed between tasks inherent to cluster processing, such as message passing and synchronization, and useful computation. A fundamental component of all parallel code analysis and debugging tools is the global clock33. Global clocks allow mapping in time the relevant events of a computation. With such a mapping, it is possible to identify how the various processors of a cluster are being utilized, identify bottlenecks, distribute the load, and thus produce efficient parallel code. During the two years of this project, we developed, together with COPPE/UFRJ-Sistemas, a prototype and two patents for a sub-microsecond precision global clock implemented in hardware for clusters [34],[35].
7.1.4. Consolidation of Our Local Research Group
In 1997, we founded the high-performance computing research group at UFES. During the two years of this project (2003–2004), we consolidated the group with the creation of the High-Performance Computing Laboratory (www.lcad.inf.ufes.br).
7.1.5. Improvement of Local Research Infrastructure
In 2003, the Enterprise Cluster of the High-Performance Computing Laboratory at UFES became operational13. This cluster has 65 processors and in June 2004 was ranked 53rd on clusters.top500.org.
7.2. PQ Project 2005–2007 – Computer Architectures and Advanced Memory Hierarchies
To make a large amount of memory available to programmers and allow access to this memory at high speed and low cost, a hierarchy of different types of memory is currently used (Figure 34).

At one end of the hierarchy, inside the processor, registers constitute the primary source of data and instructions. When the data and/or instruction needed for computation are not in its internal registers, the processor requests them from the Level 1 (L1) Cache(s). If they are not in L1, L2 is examined, and so on until the disk, network, or another storage or interconnection device provides the requested data or instructions (there are systems with a different number of cache levels). Typically, starting from the registers, the entire hierarchy can be treated by the programmer as a single memory with a size equal to the maximum allowed by the Instruction Set Architecture (ISA), with hardware and software structures associated with L1, L2, and the DRAM-Disk/Network/etc. interface handling the movement of data and instructions between the processor and the memory hierarchy.
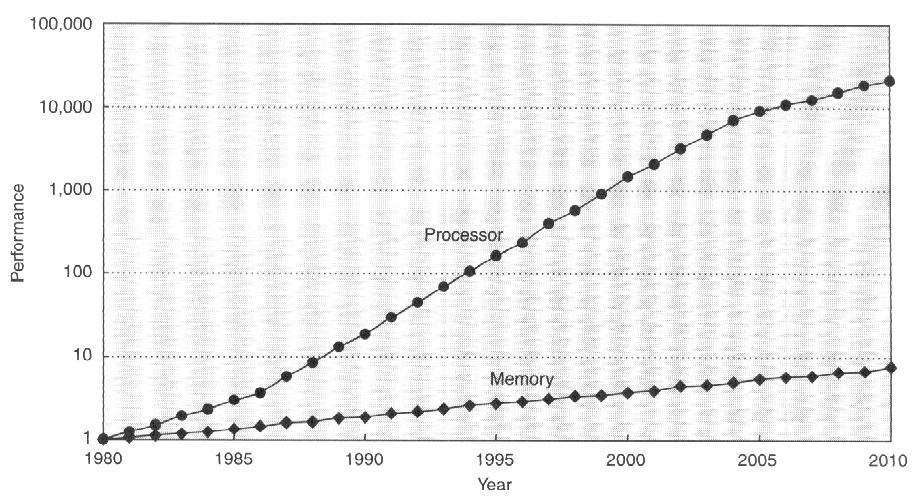
Typically, the L1 cache is small (tens of Kbytes) and operates at processor speed, while the L2 cache is on the order of tens of times larger and tens of times slower than L1 (access time equal to approximately 10 processor cycles). Today, the latency of accessing DRAM memory (or main memory) is some hundreds of times greater than the processor cycle time. This speed difference tends to increase rapidly in the near future due to the observed difference between the evolution of processor and main memory performance. This is illustrated by Figure 2, which shows the evolution of processor (Processor) and memory (Memory) performance from 1980 to 2010 (estimate) – in 1980, processor and memory performance are presented as equal because the computers (based on microprocessors) of that time did not have cache and accessed main memory directly [36].
As shown in Figure 35, the evolution of processor performance (single core) has been significantly more pronounced than that of memory performance – in many-core systems[37], the performance gap tends to grow at an even higher rate. This fact imposes a continued research effort to reduce the effect of memory latency on the performance of computational systems.
In this research project, we investigated alternatives for the dynamic exploitation of opportunities to reduce the effect of latency on the performance of computational systems in three contexts: (i) processor architectures; (ii) memory hierarchy architectures; and (iii) synchronization mechanisms. In the context of processor architectures, we extended the Dynamically Trace Scheduling VLIW (DTSVLIW) architecture to support multiple execution contexts; we also developed a new architecture that executes code in two modes, a sequential one and a dataflow one, called Dynamically Trace Scheduling Dataflow (DTSD). In the memory hierarchy context, we developed a new cache architecture that takes advantage of virtual memory concepts to reduce misses. In the synchronization systems context, we developed an innovative hardware device for thread synchronization in clusters: i.e., a system to provide barrier and lock primitives.
In addition to the research work discussed above, in this project we supervised undergraduate, master's, and doctoral students in other topics related to advanced processor architectures, high-performance computing, and cognitive science, areas of great interest to students in the Master's program in Computer Science and the Master's and Doctoral programs in Electrical Engineering at UFES.
7.2.1. Research Activities Developed in the Project
In 1998, we proposed the Dynamically Trace Scheduling VLIW (DTSVLIW) architecture9,10. This architecture uses the execution locality observed in code to exploit instruction-level parallelism. In our studies, we found that the DTSVLIW suffers more from the effects of memory hierarchy latency than the Superscalar architecture19. However, without these effects, the DTSVLIW would have better performance than the Superscalar, both in terms of ILP exploitation and energy efficiency (energy consumption per instruction)14. The observation of this impact of memory hierarchy latency on DTSVLIW performance led us to pursue two paths: the development of new processor architectures based on the DTSVLIW that are less sensitive to memory latency; and the development of new memory hierarchy architectures.
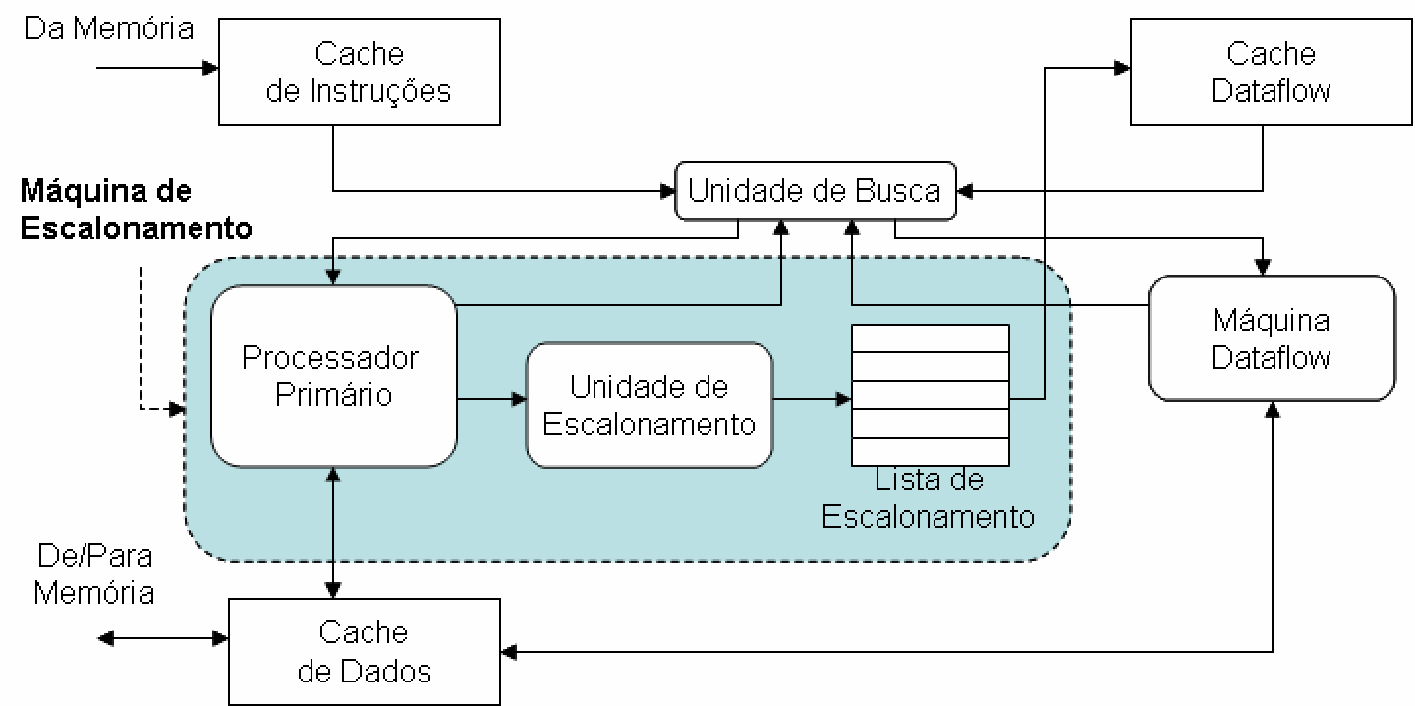
Within the first path mentioned, we proposed a DTSVLIW with multiple execution contexts (a multithreaded DTSVLIW)22,[38],[39] – in this new architecture, when a thread needs to wait for a memory access, the hardware it occupies can be yielded to another thread, improving the architecture's throughput. We also proposed a new architecture that executes code in two distinct modes, a scalar one and a dataflow one, which we called Dynamically Trace Scheduling Dataflow (DTSD) [40]. In the DTSD architecture, scalar instructions are fetched, one at a time, from the instruction cache and executed by a simple pipelined processor – i.e., the architecture's Primary Processor (Figure 36). The Scheduling Unit performs the dynamic dataflow scheduling of the path produced by the execution of these scalar instructions, thereby assembling blocks of dataflow instructions; these blocks are stored in the dataflow instruction block cache. If the same code segment needs to be executed again, the instructions from this segment can be provided by the dataflow cache and executed by the Dataflow Machine in Figure 36. The DTSD takes advantage of both the characteristics of the DTSVLIW10 and other architectures [41],[42]. Thanks to the dataflow execution mode, the negative effect caused by memory hierarchy latency is reduced, since memory access instructions will only block the execution of other instructions that depend on them, and not the execution of all instructions, as in the case of the DTSVLIW architecture.
Within the second path mentioned, we proposed a new cache memory architecture inspired by the fact that the size and latency of the last-level cache (typically level 2, or L2) are making the L2-memory interface very similar to the memory-disk interface in systems with virtual memory. In this research work, we took advantage of some concepts used in virtual memory systems to implement a new type of cache capable of reducing the impact of memory hierarchy latency and energy consumption, which we called Dynamic Block Remapping Cache (DBRC) [43].
In virtual memory systems, main memory is used as a cache for the disk. For this, the virtual memory space is divided into regions with a certain number of bytes called pages, which can be mapped to main memory, which is also divided into pages. Virtual memory pages and main memory pages, or physical memory pages, are numbered from zero to the maximum number allowed by the size of each of these memories. A hierarchy of tables allows mapping virtual memory pages to physical memory pages. When the computational system needs to access a virtual page, this table hierarchy is examined using the virtual page number as an index. If the virtual page is already mapped to a physical page, the physical page number is retrieved from the table hierarchy and can be used for access36. That is, the table hierarchy stores the translation of virtual page numbers to physical page numbers, being designed to allow any virtual page to be mapped to any physical page – this makes virtual memory systems fully associative disk caches.
A fully associative organization allows sophisticated global page replacement algorithms (which, at the time of a replacement, consider all virtual memory pages allocated in physical memory), contributing to higher hit rates. Once performed, a virtual-to-physical page translation is stored in a small translation cache (Translation Look-aside Buffer - TLB36). Subsequent accesses can find the translation in the TLB and avoid the costs associated with a table hierarchy lookup.
Similarly to the approach used in virtual memory systems, which use a table hierarchy (part of it stored on the disk itself) to map virtual memory pages to physical memory pages, the DBRC uses a table hierarchy to map physical memory blocks to L2 cache blocks43. Most of this table hierarchy is stored in L2 itself and, as in virtual memory systems, a block TLB is used to speed up access to previously performed translations. Thanks to its table hierarchy, the DBRC is fully associative and, although translations may require several clock cycles, they are infrequent. The benefits brought by full associativity and the use of global replacement algorithms implemented in hardware result in higher hit rates and lower energy consumption than conventional caches.
In the area of parallel computational systems programming, we developed or collaborated in the development of several parallel algorithms for solving computational fluid mechanics problems on computer clusters [44],[45],[46],[47],[48],[49],[50],[51],[52].
7.2.2. Other Research and Teaching Activities
In addition to the activities described so far, we also carried out other teaching and research activities in the areas of high-performance computing and cognitive science.
7.2.2.1. High-Performance Computing
Due to the need for computational resources to conduct experiments (processor architecture simulation demands great computational capacity), I joined other colleagues from the Computer Science and Environmental Engineering departments at UFES, and together we founded a High-Performance Computing research group. The actions of this group resulted in obtaining resources from the National Petroleum Agency to build a cluster of 65 processors. With resources granted by FINEP (CT-INFRA 2005), we imported 70 additional machines (35 of them quad-core and 35 dual-core) and two gigabit switches. Thus, in a period of 5 years (from 2003 to 2008), we went from 65 processors to 210. The Enterprise Cluster has been an important research tool for several researchers at UFES and at other universities in the country.
I also developed, during the period of this project, a fruitful cooperation with Prof. Cláudio Amorim, from COPPE/UFRJ-Sistemas, in the area of High-Performance Computing. This cooperation resulted in the development of a synchronization system to provide barrier and lock primitives in clusters [53].
7.2.2.2. Cognitive Science
There is great demand for supervision in the area of cognitive science in the Master's program in Computer Science, and in the Master's and Doctoral programs in Electrical Engineering at UFES. For this reason, I served as advisor for several research works in this area. The results of these works led to the development of research projects that received significant funding, as described below.
7.2.3. Other Research Projects and Relevant Achievements of the 2005–2007 Period
In this section, we briefly present other research projects in which we participated. We list only the approved projects, with disbursement of resources, in which we served as coordinator. During this period, we were responsible for research investments totaling R$ 4,196,408.00.
In this section, we also list other relevant achievements to which we contributed and that are directly or indirectly related to science, technology, and innovation.
7.2.3.1. Projects
- Automatic Classification in CNAE-Subclass (2006–2009)
- Description: The National Classification of Economic Activities (CNAE) is a hierarchical table of activities and associated codes, and its most detailed level, CNAE-Subclasses, is used as an instrument for national standardization of economic activity codes used by various public agencies of direct administration in the management and control of actions at each level of government (federal, state, or municipal). In public administration registries, CNAE-Subclass codes are assigned to all economic agents engaged in the production of goods and services, and at the Federal Revenue Service, one or more CNAE-Subclass codes must be provided when registering a new legal entity (when registering a CNPJ) or when modifying its constitutive acts. Currently, the selection and assignment of CNAE-Subclass codes is done manually by the informant themselves or by trained human coders supported by computational search tools in the CNAE-Subclass table, made available by the Brazilian Institute of Geography and Statistics (IBGE). The main objective of this project is to develop a prototype of a Computational System for the Automatic Coding of Economic Activities – SCAE. The SCAE will receive as input textual descriptions of economic activities and will produce as output the descriptors of the economic agent's activities and their respective CNAE-Subclass codes. To this end, the SCAE will generate internal system representations of the CNAE table and of the activities of the economic agent for which CNAE-Subclass codes are to be assigned for administrative use. These representations must be such that they allow identifying the correct semantic correspondence between the free textual description of the economic agent's activities and one or more items of the CNAE-Subclass table descriptors. Three techniques will be used for this internal representation: Artificial Neural Networks, Bayesian Networks, and Latent Semantic Indexing. The SCAE will also produce a certainty measure for each code and can be programmed to engage a human operator in case a certainty measure below a certain level is obtained. The coding of the establishment, obtained through SCAE-Subclass, must be exhaustive and sufficient for the identification of the economic agent's main activity, according to the pertinent rules.
- Resources: R$ 2,613,500.00 (Federal Revenue Service)
- High-Speed Metropolitan Network of Vitória – Metrovix (2005– )
- Description: The Metropolitan Network for Education and Research (REDECOMEP) initiative is part of a broader action by the Ministry of Science and Technology (MCT), and aims to deploy high-speed networks in the country's metropolitan regions served by Points of Presence of the National Research and Education Network (RNP). The initiative, coordinated by RNP, is based on the premise of deploying a proprietary optical infrastructure, interconnecting research and higher education institutions. The network deployment model provides for the construction of entirely new infrastructure and/or the use of existing ducts, cables, and optical fibers through concession of usage rights and partnerships. The Metrovix Network, which has 52.543 km of laid fiber in length, is the result of a partnership involving: the Federal Center for Technological Education of Espírito Santo; the Higher School of Sciences of Santa Casa de Misericórdia de Vitória; the Hospital of Santa Casa de Misericórdia de Vitória; the Capixaba Institute for Research, Technical Assistance, and Rural Extension; the Solar Monjardim Museum; the Municipality of Vitória; the National Research and Education Network; the State Secretariat of Science and Technology of Espírito Santo; and the Federal University of Espírito Santo. It was launched by the Minister of Science and Technology, Sergio Rezende, on August 23, 2005, and was inaugurated on August 27, 2007.
- Resources: R$ 1,103,048.00 (MCT/FINEP/RNP)
- Modernization of the Research Infrastructure in the High-Performance Computing Area at UFES (2005–2008)
- Description: This project sought to improve the infrastructure of the Enterprise Cluster at LCAD - DI/UFES (www.lcad.inf.ufes.br). Through it, 70 machines (35 quad-core and 35 dual-core) and two gigabit switches were acquired via importation, which together will be part of the new Enterprise Cluster, currently under construction.
- Resources: R$ 270,000.00 (FINEP, CT-INFRA)
- Strengthening the High-Performance Computing and Computational Intelligence Areas of the Graduate Program in Computer Science at UFES (2007–2009)
- Description: The central objective of this project is to strengthen and increase the interactions between the Computational Intelligence and High-Performance Computing research lines of the Graduate Program in Computer Science at UFES, counting on the support of research groups from already consolidated graduate programs at COPPE/UFRJ and USP/São Carlos. The COPPE/UFRJ research group will primarily support and interact with the researchers in the High-Performance Computing line of the non-consolidated program, while the USP/São Carlos research group will interact with and support the researchers in the Computational Intelligence line. In the High-Performance Computing line, joint works will be carried out between the UFES and COPPE teams on the following topics: (i) new programming paradigms suitable for future parallel systems with tens or hundreds of processors implemented through multi-core integrated circuits; (ii) study and parallel implementation of new adaptive techniques, in time and space, for representing finite element mesh configurations applied to flow problems in porous media. In the Computational Intelligence line, work will be carried out in the area of knowledge discovery in databases, involving data mining, pattern recognition, and machine learning techniques. Specifically, studies will be conducted on the following topics: (i) feature selection; (ii) adaptations of classical classification techniques to the case of data with temporal variables; (iii) integration of symbolic classifiers using multi-agent systems. The integrating element of the research work to be carried out in this project will be the study and development of techniques, algorithms, methodologies, hardware, and software for the application of parallel computing in the learning stage of data mining processes, aiming to make these processes more effective.
- Resources: R$ 169,000.00 (CNPq, Casadinho)
- Automating the Measurement of Dimensions, Areas, and Volumes (2006–2007)
- Description: In this research and technology development work, the visual perception system that allows humans to mentally form a 3D image of the external world was studied. The proposal was the implementation of an artificial binocular vision system capable of emulating a restricted part of the biological visual system related to perception attributes involved with 3D vision. In the implementation, information from images captured by cameras was used to control the process of locating points of interest in these images. This control is achieved through signals generated by an artificial neural network that receives as input images pre-processed by filters. With a focus of attention of interest, other parts of the system work on constructing the 3D model and on image recognition, which allows the evaluation of characteristics of objects in the field of vision, such as: dimensions, surface areas, and volumes.
- Resources: R$ 21,100.00 (FAPES)
- New High-Performance Architectures Based on Dynamic Instruction Scheduling (2005–2007)
- Description: In this research work, we investigated new mechanisms for dynamic detection (during code execution) of opportunities for scheduling instructions for parallel execution that are not strongly affected by memory hierarchy latency. The objective of the project was to investigate mechanisms that would allow dynamic translation, via hardware, of scalar code from existing instruction set architectures to EDGE (Explicit Data Graph Execution) code, for subsequent execution on an EDGE machine also dynamically. For this, we used our experience with the DTSVLIW architecture which, in a manner equivalent to what we proposed to investigate, translates scalar code to VLIW code and subsequently executes this code in VLIW mode, dynamically. We used an experimental approach in this investigation. For this, we made use of publicly available open-source instruction set architecture simulation environments, in addition to our own simulators.
- Resources: R$ 19,760.00 (CNPq, Universal)
7.2.3.2. Other Relevant Achievements of the Period
- In 2005, we coordinated the development of the 2005–2010 Strategic Plan of UFES and, in 2006, of the Institutional Pedagogical Project and the Information and Communication Technologies Master Plan of the University.
- In 2005, we were appointed as a standing member of the Steering Committee of the SBC/IEEE International Symposium on Computer Architecture and High Performance Computing.
- In 2007, we served as guest editor of the International Journal of Parallel Programming for the special issue on the 18th SBC/IEEE International Symposium on Computer Architecture and High Performance Computing.
- In March 2007, we became a collaborating member of the Graduate Program in Electrical Engineering (PPGEE) at UFES. This allowed us to change from the status of co-advisor to advisor of the doctoral student Fábio Daros de Freitas.
- In 2006, we served as program committee coordinator of the 18th SBC/IEEE International Symposium on Computer Architecture and High Performance Computing.
- In 2005, we served as co-coordinator of the program committee for the High-Performance Computing section of the XXVI CILAMCE.
- During the entire period of this project (2005 to 2007), we served as a member of the program committee of the SBC/IEEE International Symposium on Computer Architecture and High Performance Computing, and as a member of the program committee of the SBC Workshop on High-Performance Computing Systems.
- During the entire period of this project (2005 to 2007), we served as chair of the Management Committee of the High-Speed Metropolitan Network of Vitória – Metrovix.
7.3. PQ Project 2008–2010 — Many-Core Architectures and Computational Intelligence
Until the mid-2000s, the trend in the processor industry was to use the additional transistors provided by "Moore's Law" [54],[55] to implement Integrated Circuits (ICs) containing computational systems (processor, its caches, etc.) with a single, increasingly powerful processor. However, three obstacles prevented the continuation of this trend: (i) power consumption and the consequent need for heat dissipation from the high-frequency switching of an ever-increasing number of transistors; (ii) the growing latency of the memory hierarchy; and (iii) the difficulties associated with further exploitation of instruction-level parallelism (Figure 37).
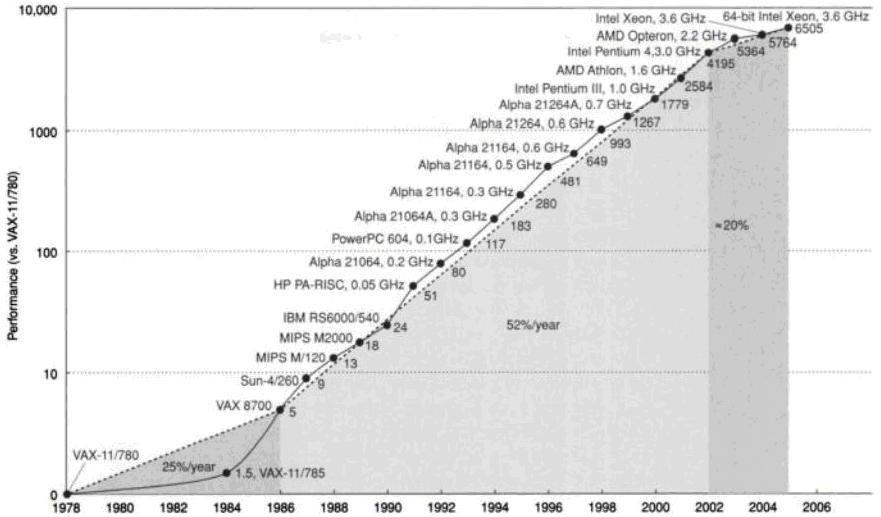
Faced with these obstacles, the global computer industry changed course in 2005, when Intel, following the example of IBM with its POWER4 processor [56] and Sun with the Niagara (UltraSPARC T1 [57]), announced that it would begin developing multi-core x86 systems [58]. Additional transistors made available by advances in IC fabrication technology would be used to implement additional x86 processors rather than a single, more powerful x86 processor, as was done previously.
7.3.1. The Brick Wall
The heat that needs to be dissipated by digital devices is proportional to their clock frequency. The continuous reduction in the size of these devices ("Moore's Law") allowed manufacturers to increase the clock frequency of commercial processors by about 1,000 times over the last 30 years. But the ability of manufacturers to dissipate the heat produced by these processors reached physical limits [59], [37], [60], [61], [62]. As a result, a significant increase in processor clock frequency is today infeasible without an immense effort in IC cooling or without the use of new materials (Figure 38). This problem is now known as "the Power Wall" and has prevented the increase in single-core system performance [37], [61], [62].

Not only is the increase in clock frequency compromised, but so is the improvement in memory hierarchy performance. For decades, memory hierarchy performance has been growing less than processor performance. Today, memory access latency is hundreds of times greater than processor cycle time. This difference tends to increase in the future since, with more cores on a single IC, the need for higher data transfer rates is growing [63], [62]. This problem is known as "the Memory Wall" [64],[65].
Processor architectures capable of executing multiple instructions in parallel, out of order, and speculatively have contributed significantly to the increase in computer performance observed in recent decades. However, using more transistors to implement these architectures has not resulted in greater exploitation of the instruction-level parallelism available in applications36. This problem is now known as "the ILP Wall" 37,36,60.
David Patterson summarized the three problems discussed above in the expression: "the Power Wall" + "the Memory Wall" + "the ILP Wall" = "the Brick Wall for serial performance" 60. Although all evidence points to the continued validity of Moore's Law at least until 2024 [66], without visible advances in overcoming the aforementioned obstacles, the industry was left with no alternative but to implement an increasing number of cores on a single IC to continue providing the exponential improvement in computational system performance that we have all become accustomed to.
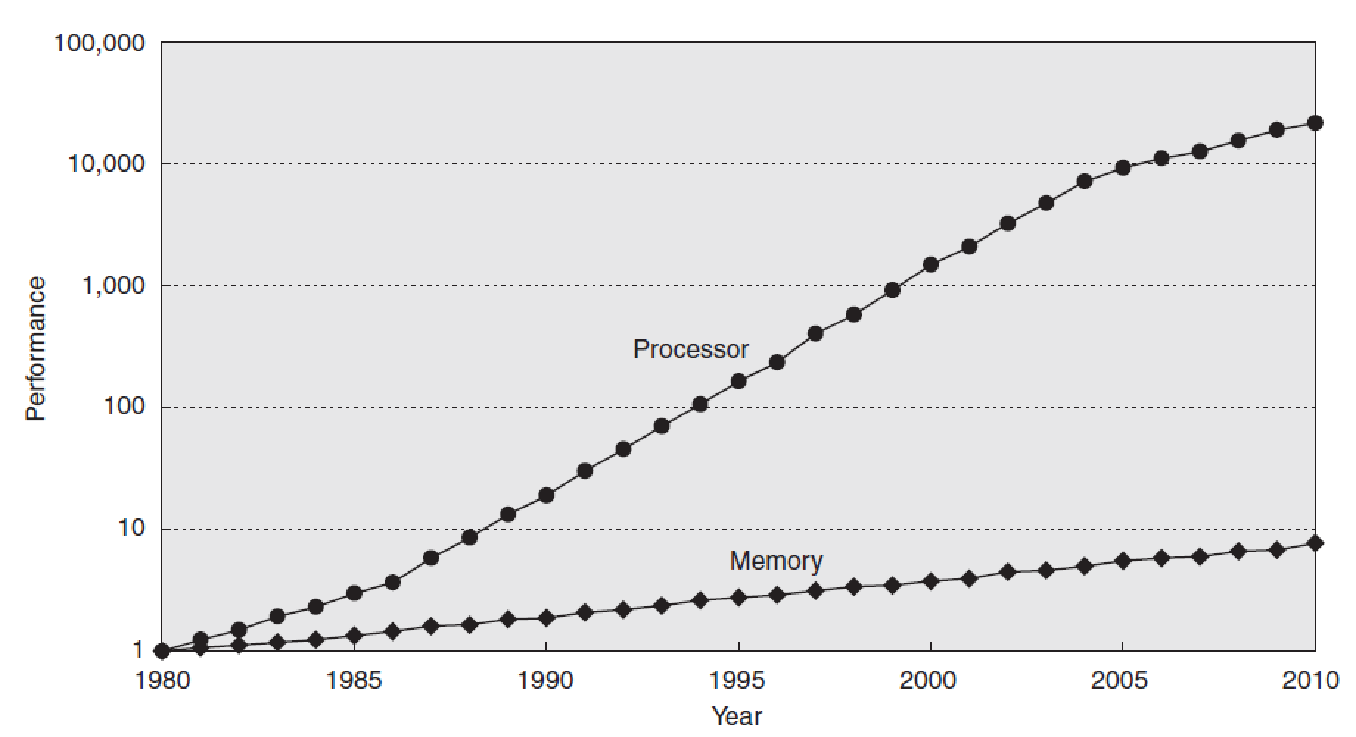
7.3.2. Research Work Developed
In the period 2008–2010, as advocated by the research project "Architecture of Computing Systems with Many Processing Cores on a Single IC," we investigated processor architectures and memory hierarchy of parallel systems, programming strategies for many-core systems, and computational intelligence applied to the problems of automatic text categorization, investment portfolio formation, and artificial vision.
7.3.3. Detailed Account of the Research Activities Carried Out in the Project
In the research productivity project "Architecture of Computing Systems with Many Processing Cores on a Single IC," we worked in three major research areas: computer architecture, high-performance computing, and computational intelligence.
7.3.3.1. Computer Architecture
Still in the area of computer architecture, we advanced our studies on the architecture we proposed that schedules execution paths (traces) from multiple threads into Very Long Instruction Word (VLIW) instruction blocks (the mDTSVLIW architecture [67]), and on the processor architecture we proposed that features a hybrid execution model incorporating, within the same architecture, control-flow and data-flow mechanisms (the Dynamically Trace Scheduling Dataflow – DTSD architecture [68],[69]). Both architectures aim to exploit the instruction-level parallelism available in applications while seeking to reduce the impact of memory latency on performance.
7.3.3.2. High-Performance Computing
In the area of high-performance computing, we investigated parallel algorithms for solving computational fluid mechanics problems on computer clusters and Graphics Processing Units (GPUs) with Compute Unified Device Architecture (CUDA [70]) technology [71],[72],[73], and developed parallel versions of artificial vision algorithms [74] and neural networks [75],[76] for CUDA GPUs.
7.3.3.3. Computational Intelligence
In the area of computational intelligence, we investigated text categorization techniques applied to the problem of classifying economic activities according to the National Classification of Economic Activities (CNAE [77]), investigated the problem of artificial visual cognition (understanding of the world and ideas through vision), and the problem of forming investment portfolios optimized for low risk and high return.
7.3.3.4. Text Categorization
The CNAE is used as an instrument for the national standardization of economic activity codes used by various public agencies of the direct administration. In tax administration records, one or more CNAE codes are assigned to all economic agents engaged in the production of goods and services, and at the Federal Revenue Service, one or more CNAE codes must be reported on the Legal Entity Registration Form (FCPJ) when registering a new legal entity or when amending its constitutive acts; the FCPJ feeds the National Registry of Legal Entities (CNPJ) of the Brazilian Federal Revenue.
Currently, in many user agencies, the determination of which codes should be assigned to each economic agent – the CNAE coding – is done manually by human coders trained for this purpose, supported by computational search tools in electronic versions of the CNAE table made available by IBGE. Manual coding done in this way, however, is very susceptible to errors. Concerned about this, the Brazilian Federal Revenue funded a research project coordinated by us in which we investigated methods for the automatic classification of economic activities described in free-text form. As a result of this project, we published a book [78], two articles in international journals [79],[80], eight papers in international and national conferences [81],[82],[83],[84],[85],[86],[75],[76], and organized two international workshops at an IEEE conference (http://www.cos.ufrj.br/~felipe/witcc2007.html, http://www.cos.ufrj.br/~felipe/ISDA2008_WITCC.html).
7.3.3.5. Artificial Visual Cognition
Within the context of the problem of artificial visual cognition, we created a neural architecture based on weightless neural networks of the Virtual Generalizing RAM (VG-RAM WNN) type [87] for face recognition [88],[89]. As far as we could verify in the literature, our VG-RAM neural architecture is currently the best-performing face recognition technique (frontal images). Our main work in this area was invited to and published as a chapter of a book on face recognition [89]. Still in the area of artificial visual cognition, we developed studies on the biology of visual cognition and new mathematical-computational models of brain areas involved in visual cognition [74].
7.3.3.6. Investment Portfolio Formation
In the area of investment portfolio formation, we reformulated the Markowitz investment portfolio formation model (Markowitz received the Nobel Prize in Economics for his work in the area [90]), creating what we called the Prediction Error-Based Portfolio Formation Model [91]. We published several papers detailing our model (including one in another application context [92]), and our main work in the area was ranked among the Top 25 (12th place) of the Neurocomputing journal in 2010 [91].
7.3.3.7. Industry Cooperation
Another noteworthy point of the 2008–2010 research productivity project was the strengthening of our relationship with a local software company with a strong presence in the industry – Mogai Tecnologia de Informação (www.mogai.com.br). Mogai was founded by UFES alumni and in 2010 employed about 40 professionals. It operates in the area of industrial automation, providing services to Petrobras, Vale, Arcelor, among other large companies. In a partnership that at the time already spanned nearly 10 years, we sought to transfer technology developed at the High-Performance Computing Laboratory of UFES (www.lcad.inf.ufes.br) to Mogai, particularly technologies in the area of computational intelligence [93]. Thanks to this effort, in partnership with Mogai, we proposed and had approved 3 subsidy projects (see Section 1.7.3.2 of this project). These projects secured jobs at Mogai and other companies, and enabled the training of master's degree holders in computer science for work in industry.
7.3.4. Other Relevant Achievements and Projects Carried Out During the Period
In this section, we list other relevant achievements that are directly or indirectly related to science, technology, and innovation, and briefly present other research projects carried out during the period of the research productivity fellowship that ended in February 2011. We list only projects with resource disbursement in which we served as coordinator or participant. During the period, we were directly or indirectly responsible for research investments totaling R$ 6,478,368.00.
7.3.4.1. Other Relevant Achievements of the Period
- In 2009, we were elevated to the level of Senior Member of the IEEE.
- In 2009, we coordinated the Committee for the Creation of the Doctoral Program in Computer Science at UFES. The program was approved by CAPES this year and will receive its first students in August of this year. Currently, we coordinate the Graduate Program in Informatics at UFES.
- In 2008, we were appointed as Honorary Visiting Fellow of the Department of Computing at City University London.
- In 2008, we were invited to deliver a talk on CUDA at the SBC/IEEE International Symposium on Computer Architecture and High Performance Computing.
- During this research productivity fellowship period (2008–2010), we served as a reviewer for the journals Neurocomputing, Cluster Computing, Parallel Processing Letters, and International Journal of Parallel Processing.
- In 2007, we served as guest editor of the International Journal of Parallel Programming for the special issue on the 18th SBC/IEEE International Symposium on Computer Architecture and High Performance Computing.
- During this research productivity fellowship period (2008–2009), we served as a member of the program committee of the following conferences: (i) SBC/IEEE International Symposium on Computer Architecture and High Performance Computing, (ii) International Conference on Soft Computing and Pattern Recognition, (iii) International Conference on Computer Information Systems and Industrial Management Applications, (iv) IEEE/ACM International Conference on Soft Computing as Transdisciplinary Science and Technology, (v) Conferencia Latino Americana de Computación de Alto Rendimiento, and (vi) Workshop em Sistemas Computacionais de Alto Desempenho.
- In 2005, we were appointed as a standing member of the Steering Committee of the SBC/IEEE International Symposium on Computer Architecture and High Performance Computing.
7.3.4.2. Projects in Progress or Completed During the Period
- Development of a 3D Localization and Mapping System Using Artificial Vision for Navigation of Robots and Unmanned Aerial or Submarine Vehicles (Subsidy)
- Description: The proposed project focuses on the development of Simultaneous Localization and Mapping methods for mobile robots. This method is known in the robotics field by the acronym SLAM. The innovation is based on Artificial Vision technology, developed by the Department of Informatics at UFES, in the Cognition Science Research Group, coordinated by Professor Alberto Ferreira De Souza. This technology has been leveraged by Mogai in the development of dimension measurement systems (distances, areas, and volumes) of various objects, such as steel plates, wood, and iron ore piles. Previously published material about these projects can be found on Professor Alberto's page (http://lattes.cnpq.br/7573837292080522), where one can learn more details about the projects "Automating the Measurement of Dimensions, Areas, and Volumes" and "Volume Measurement Based on Artificial Vision." The technology uses stereoscopic images from two digital cameras, and the great advantage of this system is that it can locate reference points in 3D space without needing any reference in the image, only knowledge of the camera setup (distance between them and calibration) and manufacturer data. The coordinate reference is the geometric center between the two cameras. Based on this technology, a related project was developed, called "Robotic Navigation According to Biological Models of Artificial Vision," by student Stiven Schwanz Dias (http://lattes.cnpq.br/1324441393849298), where a virtual mobile robot was placed in a maze having as inputs only the input from two stereoscopic cameras. The robot, processing the camera images, generates a three-dimensional map of its surrounding environment, measuring distances to obstacles, choosing the path to follow without colliding. The project was developed successfully and we will continue the research and transform it into a product that can be used for both military and civilian purposes, evolving from the Measurement by Artificial Vision products that Mogai has been developing (http://www.mogai.com.br/MOGAI-VisaoArtificial.pdf). We will use Artificial Vision for real-time generation of a 3D model of the environment from 2D images. To achieve sufficient performance for the application to run in real time, parts of the software will be migrated to CUDA video accelerator cards for high-performance parallel graphics processing. The use of the Artificial Vision system has advantages over single-camera (2D) localization systems, as the 3D localization of reference points provides more data to map the surrounding environment and consequently better determine the robot's location. This characteristic offers advantages when compared to traditional odometry methods using inertial sensors or others, such as motor rotation control, and is particularly interesting for robots that move and can rotate in all directions and senses, as occurs with underwater mobile robots or even for localization and mapping systems for control of unmanned aircraft or missiles. Information such as terrain relief or known formations can be added for determination of the position and orientation of the robots. It is worth noting that the technology is entirely national, having been developed by the Cognition Science Research Group. Additionally, we will equip the solution with an inertial sensor for verification of the developed solution. The system will be tested on a robot already used at UFES, and on another to be acquired. Tests on aircraft or submersibles only if some client or partner subsidizes them. Another advantage is that the technology is entirely developed in Brazil, the result of 15 years of research developed at UFES by Professor Alberto, who will participate as a consultant in the project, and his research group, in addition to the necessary equipment (CCD cameras) being relatively inexpensive and easy to find.
- Resources: R$ 1,863,360.00 (FINEP)
- Strengthening the Areas of High-Performance Computing, Optimization, and Computational Intelligence of the Graduate Program in Informatics at UFES
- Description: This project has as its central objective to strengthen and increase the interactions between the research lines in High-Performance Computing, Optimization, and Computational Intelligence of the Graduate Program in Informatics (PPGI) of the Federal University of Espírito Santo (UFES), counting for this with the support of the Graduate Programs in Civil Engineering and Systems and Computing Engineering at COPPE/UFRJ, interdisciplinary area of High-Performance Computing. This project aims to continue the advances achieved with the project Strengthening the Areas of High-Performance Computing and Computational Intelligence of the Graduate Program in Informatics at UFES - FACADIC, supported by CNPq in the previous Casadinho call. Joint work will be carried out between the teams from UFES and COPPE involving research on modeling and simulation in high-performance computing systems on the following topics: (i) implementation strategies of the finite element method using high-performance computing; (ii) programming of many-core systems; and (iii) combinatorial scientific computing. With this project, it is expected to establish cooperation ties for the investigation of relevant scientific questions in the area of High-Performance Computing, both among the researchers from the two partner universities involved in the project and in the PPGI. The integrating elements of the research work to be carried out in this project will be the study and development of techniques, algorithms, methodologies, hardware, and software for applications of parallel computing in fluid mechanics, combinatorial optimization, and machine learning. Practical applications involve, among others, problems with multiple coupled physics (multi-physics) in fluid dynamics, prediction of the risk or future value of financial assets, classification of credit card transactions as fraudulent or not, and feature selection in recognition problems.
- Resources: R$ 140,000.00 (CNPq)
- Technical-Scientific Visit to the Department of Computing at City University London
- Description: A 30-day technical-scientific visit by researcher Alberto Ferreira De Souza, a member of the Department of Informatics at the Federal University of Espírito Santo, to the Department of Computing at City University London, in particular, to the members of the Autonomous Intelligent Systems Group. During this visit, we discussed the formulation of joint research projects with Prof. Artur d'Avila Garcez, a member of the Autonomous Intelligent Systems Group. This visit is within the context of the Project Strengthening the Areas of High-Performance Computing and Computational Intelligence of the Graduate Program in Informatics at UFES - FACADIC. The FACADIC Project has as its objective to strengthen and increase the interactions between the research lines of Computational Intelligence (IC) and High-Performance Computing (CAD) of the Graduate Program in Informatics (PPGI) at UFES.
- Resources: R$ 6,000.00 (CNPq)
- Automatic Classification in CNAE-Subclass
- Description: The National Classification of Economic Activities (CNAE) is a hierarchical table of activities and associated codes, and its most detailed level, CNAE-Subclasses, is used as an instrument for the national standardization of economic activity codes used by various public agencies of the direct administration in the management and control of actions at each sphere of government (federal, state, or municipal). In public administration records, CNAE-Subclass codes are assigned to all economic agents engaged in the production of goods and services, and at the Federal Revenue Service, one or more CNAE-Subclass codes must be reported when registering a new legal entity (when registering a CNPJ) or when amending its constitutive acts. Currently, the selection and assignment of CNAE-Subclass codes is done manually by the informant themselves or by trained human coders supported by computational search tools in the CNAE-Subclass table, made available by the Brazilian Institute of Geography and Statistics (IBGE). The main objective of this project is to develop a prototype of a Computational System for the Automatic Coding of Economic Activities – SCAE. The SCAE will receive as input textual descriptions of economic activities and produce as output the descriptors of the economic agent's activities and their respective CNAE-Subclass codes. To this end, the SCAE will generate internal system representations of the CNAE table and of the economic agent's activities for which CNAE-Subclass codes are to be assigned for administrative use. These representations must be such as to allow the correct semantic correspondence to be identified between the free-text description of the economic agent's activities and one or more items of the CNAE-Subclass table descriptors. Three techniques will be used for this internal representation: Artificial Neural Networks, Bayesian Networks, and Latent Semantic Indexing. The SCAE will also produce a certainty measure for each code and may be programmed to activate a human operator in case a certainty measure below a certain level is obtained. The coding of the establishment, obtained in the SCAE-Subclass, shall be exhaustive and sufficient for the identification of the main activity of the economic agent, according to the pertinent rules.
- Resources: R$ 2,613,500.00 (Receita Federal)
- Vitória High-Speed Metropolitan Network – Metrovix
- Description: The Metropolitan Network for Education and Research (REDECOMEP) initiative is part of a broader action by the Ministry of Science and Technology (MCT) and aims to deploy high-speed networks in the metropolitan regions of the country served by Points of Presence of the National Research and Education Network (RNP). The initiative, coordinated by RNP, has as its premise the deployment of its own optical infrastructure, interconnecting research and higher education institutions. The network deployment model provides for the construction of entirely new infrastructure and/or the use of existing ducts, cables, and optical fibers through assignment of usage rights and partnerships. The Metrovix Network, which has 52.543 km of deployed fiber in length, is the result of a partnership involving: the Federal Center for Technological Education of Espírito Santo; the Santa Casa de Misericórdia de Vitória College of Health Sciences; the Santa Casa de Misericórdia de Vitória Hospital; the Capixaba Institute for Research, Technical Assistance, and Rural Extension; the Solar Monjardim Museum; the Municipality of Vitória; the National Research and Education Network; the Espírito Santo State Secretariat of Science and Technology; and the Federal University of Espírito Santo. It was launched by the Minister of Science and Technology, Sergio Rezende, on August 23, 2005, and will be inaugurated on August 27, 2007.
- Resources: R$ 1,103,048.00 (MCT/FINEP/RNP)
- Modernization of the Research Infrastructure of the High-Performance Computing Area at UFES
- Description: This project aims to improve the infrastructure of the Enterprise Cluster of the LCAD - DI/UFES (www.lcad.inf.ufes.br). Through it, 70 machines (35 quad-core and 35 dual-core) and two gigabit switches are being acquired via import, which together will constitute the new Enterprise Cluster.
- Resources: R$ 270,000.00 (FINEP, CT-INFRA)
- Measurement System Based on Artificial Vision (Subsidy)
- Description: This proposal encompasses the transformation of the Artificial Vision research, developed by the Cognition Science Research Group of the DI-UFES, into a market product, with application in some areas where Mogai already operates (steel, mining, and forestry). Artificial vision is an image processing tool and differs from other image processing technologies available on the market by using a pair of digital cameras instead of a single camera for inputting images into the computer. The system is inspired by the natural model of human vision, where we have two eyes so that the brain can identify differences in the two images and thereby create the notion of depth and spatial localization in three-dimensional space, fundamental for our interaction with the environment around us. Existing single-camera systems on the market work only on the characteristics of the pixels that form the two-dimensional image, not taking into account that the image depicts a three-dimensional world. This limitation makes existing technologies (single-camera) inflexible and their application requires that quite rigorous operating conditions be respected, such as: distance to the object of interest, positioning of the object in relation to the camera, among others. The product we are proposing stands out for its flexibility, as it will be capable of working under poorly controlled operating conditions, allowing better measurement results compared to usual technologies. As an example, we can cite the measurement of iron ore piles, an application of interest to Vale do Rio Doce and for whom Mogai has already submitted a development proposal based on the technology. An iron ore pile is entirely irregular, and its measurement involves the use of topography, which is a slow, manual process that poses a risk of accident, as the topographer must climb on top of a pile of more than 12 meters in height to measure it. No single-camera application could measure the volume of a pile with such characteristics.
- Resources: R$ 292,360.00 (FAPES)
- Strengthening the Areas of High-Performance Computing and Computational Intelligence of the Graduate Program in Informatics at UFES
- Description: This project has as its central objective to strengthen and increase the interactions between the research lines of Computational Intelligence and High-Performance Computing of the Graduate Program in Informatics at UFES, counting for this with the support of research groups from already consolidated graduate programs at COPPE/UFRJ and USP/São Carlos. The research group from COPPE/UFRJ will support and interact fundamentally with the researchers of the High-Performance Computing line of the non-consolidated program, while the research group from USP/São Carlos will interact with and support the researchers of the Computational Intelligence line. In the High-Performance Computing line, joint work will be carried out between the UFES and COPPE teams on the following topics: (i) new programming paradigms suitable for future parallel systems with dozens or hundreds of processors implemented through multi-core integrated circuits; (ii) study and parallel implementation of new adaptive techniques, in time and space, of finite element mesh configuration representation applied to flow problems in porous media. In the Computational Intelligence line, work will be carried out in the area of knowledge discovery in databases, involving data mining techniques, pattern recognition, and automatic learning. Specifically, studies will be conducted on the following topics: (i) feature selection; (ii) adaptations of classical classification techniques to the case of data with temporal variables; (iii) integration of symbolic classifiers using multi-agent systems. The integrating element of the research work to be carried out in this project will be the study and development of techniques, algorithms, methodologies, hardware, and software for the application of parallel computing in the learning stage of data mining processes, aiming thereby to make these processes more effective.
- Resources: R$ 169,000.00 (CNPq, Casadinho)
- Automating the Measurement of Dimensions, Areas, and Volumes (Subsidy)
- Description: In this research and technology development work, the visual perception system that allows humans to mentally form a 3D image of the external world will be studied. The proposal is the implementation of an artificial binocular vision system capable of emulating a restricted part of the biological visual system related to the perception attributes involved in 3D vision. In the intended implementation, information from images captured by cameras will be used to control the process of locating points of interest in these images. This control will be achieved through signals generated by an artificial neural network that receives as input the images pre-processed by filters. In possession of a focus of attention of interest, other parts of the system will act in the construction of the 3D model and in image recognition, which will allow the evaluation of characteristics of objects in the field of vision, such as: dimensions, surface areas, and volumes.
- Resources: R$ 21,100.00 (FAPES)
7.4. PQ Project 2011–2014 — Computational Intelligence and High-Performance Computing
In the research productivity project that ended in February 2014, we worked mainly in two major areas: computational intelligence and high-performance computing. We also participated in important scientific competitions and carried out relevant cooperation activities with other research groups and with industry.
7.4.1. Research Activities in Computational Intelligence
In the area of computational intelligence, we investigated the problems of artificial visual cognition, Simultaneous Localization and Mapping (SLAM), autonomous robot navigation, and optimized investment portfolio formation.
7.4.1.1. Artificial Visual Cognition
In the area of artificial visual cognition, we conducted research activities in image recognition, stereo vision, and visual search.
7.4.1.2. Image Recognition
We employed our VG-RAM WNN approach [87] for face recognition [88],[89] in an access control system that uses only facial biometrics as an access key [94]. Access control systems normally employ verification, that is, the individual who desires access provides their identity (an access key) and has their face image captured, and the system verifies whether the captured image sufficiently resembles the image in the system's database associated with the provided access key. To evaluate the feasibility of an access control system based solely on facial biometric data, we developed a prototype of this system that operates fully automatically in three stages: (i) detection of a face in a scene, (ii) recognition (identification) of the detected face, and (iii) Bayesian inference to determine whether access should be granted or not. The Bayesian inference implemented consists of computing the probability that the activation pattern of the VG-RAM WNN neurons corresponds to that of an individual who should have access.
A video showing this system in operation can be viewed at http://youtu.be/wsWpgnqh9xg (access control for an autonomous vehicle). Although there are currently commercially available access control systems based on facial biometrics, as far as we could examine in the literature, the combination of techniques we employed to solve the problem is unique and the results we obtained are relevant.
Still in the area of image recognition, we proposed an approach for traffic sign recognition based on VG-RAM WNN [95],[96]. Traffic sign recognition is a challenging and relevant real-world problem for the development of intelligent transportation systems. The challenge lies in the fact that, although there is a wide range of variations in terms of color, shape, and the presence of pictograms and text to facilitate the recognition of each sign class, there are subsets of classes (e.g., speed limit traffic signs) that are very similar. Moreover, the recognition system needs to deal with large appearance variations caused by changes in illumination, partial occlusions, rotations, weather conditions, etc.
Our VG-RAM WNN architecture for traffic sign recognition models the retinotopic retina-to-primary visual cortex (V1) mapping, that is, the mapping of retinal images to V1. It also models the synaptic interconnection pattern observed in many classes of biological neurons present in V1 [30],[95],[96].
We evaluated the performance of our VG-RAM WNN approach for traffic sign recognition using the German Traffic Sign Recognition Benchmark (GTSRB) (http://benchmark.ini.rub.de) [97],[98]. At the time of publication of our results, our approach was ranked in fourth place in the GTSRB. It is important to note that, at the time, the second and third places were held by human classifiers.
7.4.1.3. Stereo Vision
We proposed a technique for solving the stereo correspondence problem [99] based on VG-RAM WNN [87]. The stereo correspondence problem consists of locating the image of 3D world points in images captured by two or more cameras positioned at different locations in space. The differences in the positions of the images of these points in each camera's images, or disparity, together with information about the projective geometry of the cameras and their relative positions in space, can be used to compute the 3D position of points in the world, enabling the reconstruction of the 3D world surface captured by the cameras. Our VG-RAM WNN approach addresses the dense binocular stereo correspondence problem, that is, it computes a disparity estimate for each pair of corresponding pixels in a stereo image pair (Figure 40).



Figure 40: Stereo correspondence [99]. First two images: Stereo image pair. Last image: Disparity map.
Our VG-RAM WNN architecture for stereo correspondence models the human visual system's capacity for depth perception mediated by stereoscopic vision30. We analyzed the performance of our VG-RAM WNN approach for stereo correspondence using the Middlebury Stereo Datasets (http://vision.middlebury.edu/stereo/data/) [100]. Even without addressing the occlusion and discontinuity problems in the stereo image pairs examined, our neural architecture achieved relevant performance in the online evaluation of Middlebury University (http://vision.middlebury.edu/stereo/) [99], which is a reference in the area of stereo correspondence.
7.4.1.4. Visual Search
We also proposed a visual search technique [101] based on VG-RAM WNN. Our VG-RAM WNN architecture for visual search implements the computational equivalent of the eye movements known as saccadic movements, which rapidly shift the fovea of our eyes (the fovea is the central region of the retina that has the highest density of receptors and therefore provides the highest visual acuity) to a visual target of interest30. To this end, our architecture models the retinotopic mapping of images from the retina to the superior colliculus (SC30), whose neural activation pattern predicts and anticipates saccadic movements.
Recent neurophysiological evidence (Marino, Trappenberg, Dorris, & Munoz, 2012) suggests that, before a saccade, cells in the SC are activated and a "winner-takes-all" behavior results in the selection of a point in the visual field retinotopically mapped in the SC – this point is the target of the saccade. In our VG-RAM WNN approach for visual search, after a procedure equivalent to the winner-takes-all behavior observed in the SC, the coordinates of a point in the image possibly belonging to the object of interest (saccade target) are computed from the output of the VG-RAM WNN neurons. The model's fovea is shifted (saccade) to this point and the saccade target is computed again. This procedure is repeated a maximum number of times or until the model's fovea no longer shifts.
We employed our VG-RAM WNN approach for visual search in the implementation of a traffic sign detection system [101] and analyzed the performance of this system on the German Traffic Sign Detection Benchmark (GTSDB) (http://benchmark.ini.rub.de) [102]. Using only 12 traffic sign images for training, our system was ranked among the top 16 methods participating in the German Traffic Sign Detection Competition (prohibitory category), part of the International Joint Conference on Neural Networks (IJCNN) 2013 – all other methods used 600 images for training. Videos demonstrating these results can be viewed at http://youtu.be/H_LdE8fcbF4 (which illustrates a single training session and several subsequent saccades to a traffic sign from various positions in the scene) and http://youtu.be/SZ9w1XBWJqE (which illustrates the exploitation of symmetry present in detected traffic signs in order to find their center).
7.4.2. SLAM and Autonomous Robot Navigation — IARA
This project included the implementation of an experimental robotic platform for developing research in the area of SLAM and autonomous robot navigation. Thanks to the efforts of the research group we coordinate, we developed and had approved the PRONEX research project entitled "Center of Excellence in High-Performance Computing and its Application in Scientific Computing and Computational Intelligence (NECAD)," which enabled the implementation of the experimental robotic platform named Intelligent Autonomous Robotic Automobile – or IARA. We developed the entire codebase for SLAM and autonomous navigation of IARA.
IARA is an experimental robotic platform based on an adapted passenger car. This adaptation involved installing on the car: (i) mechanisms to control the accelerator, brake, steering wheel position, etc.; (ii) sensors; (iii) computers to receive sensor data and control the car; and (iii) power sources for the computers and sensors.
We investigated numerous companies in Brazil and abroad and did not find any that offered us technology similar to or superior to that offered by the American company Torc Robotics (http://www.torcrobotics.com) for actuating the actuators (steering wheel, accelerator, brake, among others) of the car and providing electrical power to feed the computers and sensors necessary for our studies. At the time of acquisition, Torc's technology for passenger vehicles only operated with the Ford Escape Hybrid automobile. Thus, we imported this automobile (Figure 41(a)) from the USA already with the actuation and power supply technologies installed by Torc (Figure 41(b)).

(a)

(b)
As sensors, we chose the Bumblebee XB3 stereo video cameras from Point Grey (http://www.ptgrey.com) (Figure 42(a)), the Light Detection And Ranging (LIDAR) HDL-32E from Velodyne (http://www.velodynelidar.com) (Figure 42(b)), and the GPS-aided Attitude and Heading Reference System (AHRS/GPS) MTi-G from Xsens (http://www.xsens.com), which includes a GPS and an Inertial Measurement Unit (IMU) (Figure 42(c)). To control the robotic platform, we opted for a mini-supercomputer (mini cluster) composed of four Dell Precision R5500 computers (Figure 42(d)) – high computational performance is important due to the demand typically observed in algorithms involving image processing (one of our main topics of study is artificial visual cognition).
Figure 43 shows our experimental robotic platform, which has capabilities equivalent to the most modern ones currently under study in the world.

(a)

(b)

(c)

(d)



7.4.2.1. IARA's Control System
We developed the entire control system for IARA to operate autonomously. This system is composed of several modules that were implemented using state-of-the-art probabilistic techniques for localization and navigation of autonomous vehicles (Figure 44).
We installed on IARA the sensors (in yellow in Figure 44): GPS and IMU, part of the Xsens AHRS/GPS; front and side Bumblebee stereo cameras; Velodyne LIDAR (Figure 43); and car speed and steering wheel angle sensors, v and phi (the latter two sensors are part of the solution acquired from Torc). The data from these sensors are preprocessed by drivers (in red in Figure 44 – all developed by our research group) and sent to filters (in green in Figure 44 – all developed by our research group), which receive as input data from one or more sources and generate as output processed versions of this data.
We developed the filters: GPS x,y,z, which transforms GPS latitude and longitude data into UTM coordinates; Visual Odometry, which, from stereo images, produces odometry data for IARA (6D position over time); Stereo [99], which, from stereo images, produces 3D depth maps; Road Mapper [103], which, from depth maps and odometry data, produces an obstacle and free-area map ahead of IARA; Localizer, which localizes IARA in 6D in the world; 2D Mapper, which creates an online map of the road and obstacles around IARA; Path Planner [104], which generates IARA's navigation signals; Obstacle Avoider, which filters low-level control data at high speed to avoid imminent collisions; and Health Monitor, which continuously checks the proper functioning of all modules, automatically restarts modules that are not operating correctly, and informs the user about its actions.
IARA's User Interface allows specifying tasks for it to execute. To assist the user in task specification, IARA's Control System has a Road Definition Data File Manager (RDDF Manager). Under the control of the User Interface, the RDDF Manager stores and allows the manipulation of data collected by IARA when in learning mode or in autonomous mode. In learning mode, IARA is driven by a human driver, stores all sensor data, and builds maps of the traveled environments. In autonomous mode, the user can control IARA from inside it and from outside it, via the Internet. When inside IARA, the user can specify a destination on a map using a mouse; and when outside IARA, the user can specify a destination by touching the User Interface via tablet or mobile phone. The User Interface also allows viewing and controlling various other aspects of IARA's operation.
For the implementation of the various modules mentioned above, we employed the Carmen framework, developed by Sebastian Thrun's group at Carnegie Mellon and later at Stanford (http://carmen.sourceforge.net). The development of the open-source version of Carmen was discontinued in 2008; however, this framework guaranteed its developers victory in the Defense Advanced Research Projects Agency (DARPA) Grand Challenge of 2005 (http://archive.darpa.mil/grandchallenge05) and second place (although it completed the course in first place) in the DARPA Urban Challenge (http://archive.darpa.mil/grandchallenge/index.asp). Thus, although other open-source frameworks are now available and maintained, we chose to continue the development of Carmen at the High-Performance Computing Laboratory (LCAD) of UFES (http://www.lcad.inf.ufes.br/wiki/index.php/Carmen_Robot_Navigation_Toolkit). Today, we make available and maintain an LCAD version of Carmen (https://github.com/LCAD-UFES/carmen_lcad).
Carmen enables the development of systems composed of multiple executable programs (or modules) that communicate according to the publish-subscribe paradigm. According to this paradigm, a sensor module, for example, can be implemented through an independent executable program that sends (publishes) messages with data obtained from the sensor to any modules that subscribe to these messages. A filter module can subscribe to messages from several modules, manipulate ("filter") these messages with algorithms of interest, and publish messages with its results to several other modules that require them. An actuator module can receive messages from several other modules, execute algorithms on them, and use the result to control something in the real world.
A module that publishes a message does not need to know who receives it; thus, problems such as deadlock and starvation that complicate the programming of distributed systems (autonomous vehicle control systems are inherently distributed) are avoided. IARA's modules run on a mini-supercomputer cluster with nodes running the Linux Ubuntu 12.4 LTS operating system and a real-time kernel (https://rt.wiki.kernel.org). The use of a real-time operating system facilitates the implementation of algorithms that deal with time, as is the case with most algorithms implemented by IARA's modules.
We tested the various implemented modules in our autonomous vehicle simulation framework (not presented here) and on IARA itself. Videos demonstrating various results of these tests can be viewed on LCAD's YouTube channel: http://www.youtube.com/user/lcadufes. The results achieved with IARA were covered by print and television media. The various reports can be read/watched at http://goo.gl/o048gt.
7.4.2.2. SLAM
We proposed a SLAM approach for autonomous vehicles based on a state-of-the-art probabilistic SLAM technique and on our mathematical-computational models of vergence and 3D reconstruction, visual search [101], visual exploration, and image recognition [88],[89],[95],[96], which we called "Neural SLAM" [105]. Our Neural SLAM system employs only stereo video cameras, which are currently capable of capturing images with millions of pixels and have a substantially lower cost than other sensors, in addition to being biologically plausible.
7.4.2.3. Optimized Investment Portfolio Formation
In the area of optimized portfolio formation, we employed Harry Markowitz's mean-variance model in the formation of macro-portfolios of taxes with optimal shares of tax aggregates in federal revenue collection [106]. These optimal macro-portfolios, or efficient macro-portfolios, are those that produce the lowest instability in revenue growth for a given expected growth rate, or the highest expected growth rate for a given acceptable revenue instability. We evaluated the effect of the optimal shares proposed by our model on the revenue collection of a set of tax aggregates and compared their growth profile with the results obtained by the Federal Government. Our experimental results showed that, in the analyzed context, the tax structure of federal revenue collection operates at a suboptimal level of instability-growth. Through efficient diversification of the revenues of tax aggregates, it was possible to obtain, in the conservative profile, a cumulative revenue growth 28 percentage points above the realized cumulative growth of the same tax aggregates and with only 25% of its instability – a four-times-lower risk. In the moderate profile, a cumulative growth 33 percentage points above was achieved, for the same level of instability [106].
We also developed a neural architecture based on VG-RAM WNN for predicting the future return of stocks [107]. We evaluated the performance, in terms of prediction quality, of our neural architecture in predicting the weekly returns of 49 stocks in the IBOVESPA index and obtained the same average error level as weighted neural predictors previously evaluated in the literature. However, our VG-RAM predictors are approximately 5,000 times faster than standard weighted neural predictors, which makes the use of VG-RAM viable in high-frequency trading systems [108].
7.4.3. Research Activities in High-Performance Processing
In the area of high-performance processing, we investigated strategies for programming computational systems with many processing cores. In this topic, we evaluated parallel algorithms for solving computational fluid mechanics problems [109] and stereo vision[110] for computer clusters and Graphics Processing Units (GPUs) with Compute Unified Device Architecture (CUDA [111]) technology.
CUDA is a recent GPU architecture capable of executing general-purpose parallel programs written in the C programming language with a small extension. The Single Instruction Multiple Thread (SIMT [112]) architecture of CUDA GPUs allows the implementation of general-purpose C+CUDA code with massively scalable multiple threads. Currently, CUDA GPUs have arrays with more than one thousand processing cores (called stream processors) and peak performance exceeding 1 Tflop/s.
7.4.3.1. Parallel Algorithms for Solving Computational Fluid Mechanics Problems
We investigated two parallel implementations of the time-dependent 2D advection and diffusion problem using finite elements: one for multi-core machine clusters and one for CUDA GPUs, and compared their performances in terms of time and energy consumption [109]. The parallel implementation in CUDA was developed from the multi-core machine cluster version. Our experimental results showed that, in this class of finite element problems, a desktop computer with a single CUDA GPU can achieve greater performance than a 24-node (96 cores) multi-core machine cluster manufactured at approximately the same time. Furthermore, the CUDA implementation consumes less than one-twentieth of the energy (Joules) consumed by the cluster implementation while solving an entire instance of the finite element problem considered.
7.4.3.2. Stereo Vision
We examined two parallel versions of the Constant Space Belief Propagation (CSBP – one of the best currently known stereo vision algorithms) algorithm [110]: one in OpenMP and another in C+CUDA. For 640x480 pixel images, the sequential version achieved a performance of 1.16 Frames Per Second (FPS), the parallel OpenMP version achieved a performance of 3.7 FPS, while the parallel C+CUDA version achieved a performance of 17.3 FPS on high-performance desktop machines. These results are relevant because they contribute to enabling the implementation of autonomous vehicles with camera-type sensors.
7.4.4. Participation in International Scientific Competitions
We participated in an important scientific competition held by DARPA called the DARPA Virtual Robotics Challenge (VRC – http://goo.gl/s7GhdX), part of the DARPA Robotics Challenge (DRC – http://www.theroboticschallenge.org/). The main objective of the DRC was to develop humanoid robots capable of executing complex tasks in human-built environments that are in degraded and dangerous states, such as those resulting from accidents like the Fukushima nuclear power plant disaster. Competitors in the DRC were required to implement robots that could use tools and equipment commonly available in human environments, ranging from hand tools to vehicles, with emphasis on adaptability to available tools. The VRC was a part of the DRC that involved challenges equivalent to those of the DRC, but in a virtual environment. Hundreds of teams participated in the VRC, which ended on June 27, 2013. Our team, named Br Robotics Team (http://www.lcad.inf.ufes.br/wiki/index.php/DARPA), placed 12th in the VRC.
The teams classified up to 9th place in the VRC received an Atlas robot from Boston Dynamics and an additional US$750,000.00 to continue competing in the DRC, which ended in December 2014.
We also participated in the competitions associated with the German Traffic Sign Recognition Benchmark (GTSRB) and German Traffic Sign Detection Benchmark (GTSDB), as previously mentioned above.
7.4.5. Academic and Industry Cooperations
We developed and coordinated research projects with other research groups in Brazil and abroad. The PRONEX project "Center of Excellence in High-Performance Computing and its Application in Scientific Computing and Computational Intelligence" was a research project funded by FAPES and CNPq, and was carried out in partnership with COPPE/UFRJ (Systems Engineering and Computing Program, Prof. Claudio Amorim, and Graduate Program in Civil Engineering, Prof. Álvaro Coutinho) and USP (Polytechnic School, Advanced Perception Laboratory, Prof. Jun Okamoto). The project "Consolidation of Research Lines in High-Performance Computing, Optimization, and Computational Intelligence at PPGI/UFES" was funded by CNPq and carried out in partnership with COPPE/UFRJ (Systems Engineering and Computing Program, Prof. Claudio Amorim, and Graduate Program in Civil Engineering, Prof. Álvaro Coutinho). The project "Assisted Navigation of a Passenger Car Controlled by a Brain-Computer Interface" was funded by UFES and carried out in partnership with Universidad Técnica Federico Santa María (UTFSM), Chile, and the Graduate Program in Electrical Engineering at UFES (Prof. Teodiano Freire Bastos Filho).
We participated in research and economic subsidy projects with Mogai Tecnologia de Informação (www.mogai.com.br). During this project, we supervised 2 doctoral students and 2 master's students who worked at Mogai. A former employee of the company obtained a doctorate abroad and is now a professor in the Department of Computer Science at UFES and a member of LCAD; a former advisee from the Master's program in Computer Science at UFES who was an employee of Mogai is now a professor with a doctorate at the Federal Institute of Education of Espírito Santo and a research partner of LCAD, among several other former students and former employees of Mogai who benefited from our partnership with this company.
7.4.6. Summary of Results Achieved
During the research productivity grant that ended in February 2014, we published 5 articles in international journals, 7 articles at international conferences, and organized 4 books: the books of the Jornadas de Atualização em Informática (JAI) of the Brazilian Computer Society (SBC) of 2011 and 2012, JAI'2011 and JAI'2012, and the proceedings of the IEEE 23rd International Symposium on Computer Architecture and High Performance Computing – SBAC-PAD'2011 and of the XII Simpósio em Sistemas Computacionais – WSCAD-SSC'2011. In the area of personnel training, we graduated 5 master's students and 5 undergraduate research students. We also participated in important international scientific competitions and developed cutting-edge technology in the area of autonomous robotics. We strengthened existing partnerships and established new scientific partnerships with research groups in Brazil and abroad. In the area of outreach, we strengthened partnerships with industry through various subsidy projects.
7.4.7. Other Relevant Achievements and Ongoing or Completed Projects in the Period
In this section, we list other relevant achievements that are directly or indirectly related to science, technology, and innovation, and briefly present other research projects ongoing or completed during the period of the research productivity grant 2011–2013. We list only projects with disbursement of resources and in which we served as coordinator or member of the research team. During this period, we were directly or indirectly responsible for research investments totaling R$3,339,134.90.
7.4.7.1. Other Relevant Achievements in the Period
- I was invited and accepted to participate as an evaluator in the CAPES 2013 Triennial Evaluation of Brazilian Graduate Programs.
- I served as Director of Research at UFES.
- I served as one of the coordinators of the Jornadas de Atualização em Informática (JAI) of the Brazilian Computer Society (SBC) in 2011 and 2012.
- I served as a reviewer for the journals Neurocomputing, Cluster Computing, Parallel Processing Letters, and International Journal of Parallel Processing.
- I served as General Chair of the 23rd IEEE International Symposium on Computer Architecture and High Performance Computing.
- I served as General Coordinator of the XII Workshop em Sistemas Computacionais de Alto Desempenho.
- I served as a program committee member of the conferences: SBC/IEEE International Symposium on Computer Architecture and High Performance Computing, and Workshop em Sistemas Computacionais de Alto Desempenho.
- I served as a standing member of the Steering Committee of the SBC/IEEE International Symposium on Computer Architecture and High Performance Computing.
- I coordinated the Br Robotics Team, which placed 12th in the DARPA Virtual Robotics Challenge (VRC), part of the DARPA Robotics Challenge (DRC).
7.4.7.2. Ongoing or Completed Projects in the Period
- PRONEX: Center of Excellence in High-Performance Computing and its Application in Scientific Computing and Computational Intelligence (Research Project – Coordinator)
- Description: With this project, we aimed to create and consolidate the "Center of Excellence in High-Performance Computing and its Application in Scientific Computing and Computational Intelligence" (NECAD) at UFES through the acquisition of additional infrastructure and the conduct of research, together with researchers from COPPE/UFRJ, in high-performance computing and its application in scientific computing and computational intelligence. Today, there is a growing need for new techniques within the field of scientific computing to enable simulations of problems involving multiple spatial and temporal scales and multiple coupled physics. To contribute in this area, we will advance our investigations into new formulations and implementation techniques for the finite element method, and new solution strategies for the linear systems resulting not only from finite element formulations but also from finite difference or finite volume formulations. With the support of this project, we will also advance our investigations into mathematical-computational models of visual cognition applied to the problem of Simultaneous Localization and Mapping (SLAM) of autonomous vehicles. To this end, we will deepen our studies on the biology of visual cognition and on new mathematical-computational models of brain areas involved in visual cognition. These models, given their complexity, demand great computational effort and therefore require high-performance computing. With the creation of NECAD, efforts will be channeled toward the development of new numerical libraries to support code development for solving multi-physics problems, multi-scale simulation, fast solvers, as well as prototypes of computational systems for large-scale simulations. We will also seek to extend the state of the art in Artificial Visual Cognition through the implementation of an autonomous vehicle based on a commercial automobile and its use in scientific research that supports the implementation and integration of vergence and 3D reconstruction, visual search, and image recognition systems in SLAM systems for autonomous vehicles. Such systems have applications in the automotive industry, military defense equipment industry, as well as applications in the automation of numerous tasks in industry and commerce in general that require autonomous vehicles. We will also seek with this project to advance our research on many-core system programming and applications of Virtual Generalizing Random Access Memory Weighless Neural Networks (VG-RAM WNN). The creation of NECAD will contribute to the training of new researchers, doctoral and master's graduates, and undergraduate research students, as well as many other professionals at the undergraduate and graduate levels.
- Funding: R$ 814,580.00 (FAPES/CNPq)
- Assisted Navigation of a Passenger Car Controlled by a Brain-Computer Interface (Research Project – Coordinator)
- Description: A Brain-Computer Interface (BCI) is a non-muscular communication channel for transmitting signals from the brain to the external world. It transforms mental decisions into control signals through the analysis of the bioelectrical activity of the brain, allowing its user to interact with the interface itself through graphical resources, for example. A BCI operates based on an electroencephalogram (EEG) signal paradigm, which can be motor imagery, mu rhythm variation, or evoked potentials. Among the evoked potentials, the Steady State Visual Evoked Potentials (SSVEP) stand out. These potentials reflect, in the EEG signal, the frequency of a visual stimulus observed on a tablet by the user. A BCI based on these potentials is called a BCI-SSVEP. A BCI-SSVEP had already been developed by the Intelligent Automation Laboratory (LAI) of the Graduate Program in Electrical Engineering (PPGEE) at UFES for commanding a robotic wheelchair. On the other hand, the High-Performance Computing Laboratory (LCAD) of the Graduate Program in Computer Science (PPGI) at UFES has a Ford Escape Hybrid passenger vehicle equipped with steering wheel, accelerator, brake, gear, headlights, horn, and other actuator control systems of interest, as well as wheel rotation and steering wheel angle sensors, among other data of interest. Also already installed on the vehicle are stereo video cameras, a laser sensor, a GPS, and an inertial sensor, which will be used to examine the environment around the vehicle and obtain its location, as well as simultaneously map the environment through the Simultaneous Localization and Mapping (SLAM) technique. From the maps obtained and processed, and also from the brain command signals, it will be possible to avoid obstacles and navigate the vehicle in the environment, using a high-performance computing network. Thus, in this international cooperation research project between PPGI/UFES and PPGEE/UFES and Universidad Técnica Federico Santa María (UTFSM) of Chile, we will seek to develop mechanisms for navigating a passenger car assisted by a Brain-Computer Interface (BCI) based on SSVEP and SLAM. With the completion of this research project, it is expected to provide people with disabilities the ability to drive a passenger car based on their brain signals, in traffic environments known to the hardware/software installed in the car. To enable the car's knowledge of the traffic environments of interest, SLAM algorithms and precise semi-autonomous navigation of passenger cars will be developed, based on the driver's brain command signals.
- Funding: R$ 28,834.90 (UFES)
- Consolidation of Research Lines in High-Performance Computing, Optimization, and Computational Intelligence at PPGI/UFES (Research Project – Coordinator)
- Description: This project has as its central objective the consolidation of the research lines in High-Performance Computing, Optimization, and Computational Intelligence of the Graduate Program in Computer Science (PPGI) at the Federal University of Espírito Santo (UFES), counting on the support of the Graduate Programs in Civil Engineering and Systems Engineering and Computing at COPPE/UFRJ, in the interdisciplinary area of High-Performance Computing. This project aims to continue the advances achieved with the projects "Strengthening the Areas of High-Performance Computing, Computational Intelligence, and Optimization of the Graduate Program in Computer Science at UFES (FACADOIC)" and "Strengthening the Areas of High-Performance Computing and Computational Intelligence of the Graduate Program in Computer Science at UFES (FACADIC)," supported by CNPq in previous Casadinho calls. Joint work will be carried out between the UFES and COPPE/UFRJ teams involving research on modeling and simulation in high-performance computational systems in the following topics: (i) implementation strategies for the finite element method using high-performance processing; (ii) mathematical-computational models of visual cognition applied to the problems of Simultaneous Localization and Mapping (SLAM) and navigation of autonomous vehicles. In addition, Combinatorial Optimization techniques applicable to topics (i) and (ii) will be investigated. With this project, it is expected to consolidate cooperation ties for the investigation of relevant scientific questions in the area of High-Performance Computing, both among the researchers from the two partner universities involved in the project and within PPGI.
- Funding: R$ 200,000.00 (CNPq)
- Strengthening the Areas of High-Performance Computing, Optimization, and Computational Intelligence of the Graduate Program in Computer Science at UFES (Research Project – Coordinator)
- Description: This project has as its central objective the strengthening and enhancement of interactions between the research lines in High-Performance Computing, Optimization, and Computational Intelligence of the Graduate Program in Computer Science (PPGI) at the Federal University of Espírito Santo (UFES), counting on the support of the Graduate Programs in Civil Engineering and Systems Engineering and Computing at COPPE/UFRJ, in the interdisciplinary area of High-Performance Computing. This project aims to continue the advances achieved with the project "Strengthening the Areas of High-Performance Computing and Computational Intelligence of the Graduate Program in Computer Science at UFES (FACADIC)," supported by CNPq in the previous Casadinho call. Joint work will be carried out between the UFES and COPPE/UFRJ teams involving research on modeling and simulation in high-performance computational systems in the following topics: (i) implementation strategies for the finite element method using high-performance processing; (ii) many-core system programming; and (iii) combinatorial scientific computing. With this project, it is expected to establish cooperation ties for the investigation of relevant scientific questions in the area of High-Performance Computing, both among the researchers from the two partner universities involved in the project and within PPGI. The integrating elements of the research work to be carried out in this project will be the study and development of techniques, algorithms, methodologies, hardware, and software for applications of parallel computing in fluid mechanics, combinatorial optimization, and machine learning.
- Funding: R$ 140,000.00 (CNPq)
- Development of a 3D Localization and Mapping System Using Artificial Vision for Navigation of Robots and Unmanned Aerial or Submarine Vehicles (Subsidy Project coordinated by Mogai)
- Description: The proposed project focuses on the development of Simultaneous Localization and Mapping methods for mobile robots. This method is known in the robotics field by the acronym SLAM. The innovation is based on Artificial Vision technology developed by the Department of Computer Science at UFES, in the Cognition Science Research Group. This technology has been leveraged by Mogai in the development of dimension measurement systems (distances, areas, and volumes) of various objects, such as steel plates, wood, and iron ore piles.
- Funding: R$ 1,863,360.00 (FINEP)
- Measurement System Based on Artificial Vision (Subsidy Project coordinated by Mogai)
- Description: This proposal contemplates the transformation of Artificial Vision research, developed by the Cognition Science Research Group at DI-UFES, into a market product, with applications in some areas where Mogai already operates (steel industry, mining, and forestry). Artificial vision is an image processing tool that differs from other image processing technologies available on the market by using a pair of digital cameras instead of a single camera for image input into the computer. The system is inspired by the natural model of human vision, where we have two eyes so that the brain can identify differences in the two images, and thereby create the notion of depth and spatial location, which are fundamental for our interaction with the environment around us. Existing market systems, with a single camera, work only on the characteristics of the pixels that form the two-dimensional image, without taking into account that the image depicts a three-dimensional world. This limitation makes existing technologies (single-camera) inflexible, and their application requires compliance with very rigorous operating conditions, such as: distance to the object of interest, its positioning relative to the camera, among others. The product we are proposing stands out for its flexibility, as it will be capable of working under poorly controlled operating conditions, allowing better measurement results when compared to conventional technologies. As an example, we can cite the measurement of iron ore piles, an application of interest to Vale do Rio Doce and for which Mogai has already made a development proposal based on this technology. An iron ore pile is completely irregular, and its measurement involves the use of topography, which is a slow, manual process that poses an accident risk, as the topographer must climb on top of the pile, which can be over 12 meters high, to measure it. No single-camera application could measure the volume of a pile with such characteristics.
- Funding: R$ 292,360.00 (FAPES)
7.5. PQ Project 2014–2016 — Computational Cognition for Autonomous Robots
Cognition can be defined as our capacity to understand the world and ideas through our senses and our memory of past experiences. We can roughly categorize our various cognitive abilities according to our senses, leading to categories such as visual cognition, auditory cognition, or tactile cognition. We can further categorize our cognitive abilities according to our capacity to understand, via our senses and memory of the past, concepts such as space (spatial cognition) or body movement/action (motor cognition). In this research project, currently in progress, we are investigating mathematical-computational models of systems that implement different levels/aspects of spatial cognition in autonomous robots and their (these systems') efficient real-time implementation through the use of high-performance computing.
Autonomous robots need to understand the space around them in order to navigate through it and interact with it; that is, autonomous robots need to possess cognitive capabilities. Ideally, it would be necessary for robots to possess at least visual, auditory, tactile, motor, and spatial cognition equal to or superior to ours in order to be autonomous, that is, to navigate freely and autonomously in the environment around us. However, the state of the art in robotics is still far from this. Nevertheless, with the advances achieved in recent years in the areas of SLAM and navigation [113], commercially available autonomous robots for domestic use already exist today, such as robotic vacuum cleaners (http://www.irobot.com/roomba), and the large-scale commercialization of autonomous passenger cars is already envisioned for the near future (http://www.forbes.com/sites/chunkamui/2013/01/22/fasten-your-seatbelts-googles-driverless-car-is-worth-trillions), among various other types of autonomous robots under study. All of this highlights the importance of investigating mechanisms to expand the cognitive capabilities of robots.
In this project, we proposed to advance our research in the areas of computational intelligence and high-performance computing, especially those aimed at artificial spatial cognition and its efficient implementation through high-performance computing.
7.5.1. Computational Intelligence
In the area of computational intelligence, we worked in three sub-areas: robotics, weightless neural networks, and investment portfolio formation.
7.5.1.1. Robotics
In the area of robotics, we investigated the problems of large-scale mapping [114], SLAM [105], localization using satellite images [115], in GPS-denied environments [116], and using only images and VG-RAM neural networks [117] for autonomous cars. We also investigated a human-computer interface for controlling autonomous cars [118].
7.5.1.2. Weightless Neural Networks
In the area of weightless neural networks, we investigated mechanisms to improve the time performance of VG-RAM weightless neural networks [119] and proposed a purely neural computer architecture based on VG-RAM networks [120].
7.5.1.3. Investment Portfolio Formation
In the area of investment portfolio formation, we proposed a new trading system architecture for High Frequency Trading [121].
7.5.2. Other Relevant Achievements During the Period
- I participated in the 2015 Amazon Picking Challenge (http://amazonpickingchallenge.org) as one of the coordinators of the Rutgers University team, R U Rutgers. The R U Rutgers team finished in 7th place in the competition, which involved robotics teams from around the world, with more than 40 registered teams. See a video of the robot we developed (hardware for adding sensors and grippers, development of a gripper, and all sensing, control, and planning software) at this link: https://www.youtube.com/watch?v=_bEGktiyGSE.
- I carried out a senior postdoctoral fellowship at Rutgers University, USA, from September 2014 to August 2015.
- I completed the supervision of two doctoral candidates.
- I served as a reviewer for the journals Neurocomputing, Cluster Computing, Parallel Processing Letters, and International Journal of Parallel Processing.
8. Concluding Remarks
In these more than 22 years as a professor at UFES, I have been involved in: undergraduate and graduate teaching; supervision of undergraduate research, master's, and doctoral students; coordination of and participation in multi-institutional research projects; coordination of and participation in R&D projects; coordination and creation of courses; coordination of a research laboratory; department chairmanship; vice-directorship of a center; superintendency of an institute; directorship of research; pro-rectorship of planning; among other activities.
The experience acquired over these years has given me a holistic view of the academic career, which encompasses the processes of personnel training, research development, transfer of technology and knowledge to society, and construction and management of the university at its various levels and spheres of action. At all moments of my career at UFES, teaching and research activities have been important sources of motivation for my work as a whole, especially because of the enriching interaction I have always had with students, fellow professors, and technical-administrative staff.
It has been very gratifying to see the advances achieved by UFES over all these years and to have contributed to and participated in some of them in some way, especially in the area of informatics. Looking back gives me the certainty of having made the right career choice.
9. References
[1] De Souza, Alberto Ferreira ; FRANÇA, Felipe Maia Galvão ; FERNANDES, E. S. T. . Laboratório para Ensino e Pesquisa em Microprogramação. Anais do I Seminário Nacional sobre Manutenção de Equipamentos para Ensino e Pesquisa. Rio de Janeiro, 1987. p. 454-458.
[2] De Souza, Alberto Ferreira ; FERNANDES, E. S. T. ; BARBOSA, V. C. ; VASCONCELOS, N. Q. . Micro-instruction placement by simulated annealing. Microprocessing and Microprogramming, Holanda, v. 32, n.1–5, p. 23-28, 1991.
[3] FERNANDES, E.S.T. ; DE AMORIM, C.L. ; BARBOSA, V.C. ; FRANCA, F.M.G. ; DE SOUZA, A.F. . MPH – A Hybrid Parallel Machine. Microprocessing and Microprogramming, v. 25, p. 229-232, 1989.
[4] De Souza, Alberto Ferreira ; Uma Máquina Paralela Híbrida. Anais do VIII Congresso da Sociedade Brasileira de Computação. Rio de Janeiro: Editado por Pedro Manoel Silveira, 1988. p. 315-332.
[5] AMORIM, Claudio Luiz de ; CITRO, Ricardo ; De Souza, Alberto Ferreira ; CHAVES FILHO, Eliseu Monteiro . O Sistema de Computação Paralela NCP I. Anais do V Simpósio Brasileiro de Arquitetura de Computadores e Processamento de Alto Desempenho, 1993.
[6] De Souza, Alberto Ferreira ; FERNANDES, E. S. T. . Determinação dos Parâmetros Ideais de uma Arquitetura VLIW. Anais do VI Simpósio Brasileiro de Arquitetura de Computadores e Processamento de Alto Desempenho – VI SBAC-PAD. Belo Horizonte – MG: Editado por Roberto da Silva Bigonha, 1994. p. 297-316.
[7] De Souza, Alberto Ferreira ; On the balance of VLIW architectures. Journal of Systems Architecture, The Netherlands, v. 43, p. 15-22, 1997.
[8] De Souza, Alberto Ferreira ; BATISTA, S. L. . Perfil do Curso de Engenharia de Computação da Universidade Federal do Espírito Santo. In: II Workshop sobre Educação em Informática, 1994, Caxambú – MG. Anais do II Workshop sobre Educação em Informática, 1994. p. 51-54.
[9] A. F. de Souza and P. Rounce, "Dynamically Trace Scheduled VLIW Architectures", in Lecture Notes in Computer Science, Vol. 1401, p. 993-995, 1998.
[10] A. F. De Souza and P. Rounce, "Dynamically Scheduling VLIW Instructions", Journal of Parallel and Distributed Computing, Vol. 60, No. 12, p. 1480-1511, December 2000.
[11] C. D. D. Freitas and A. F. De Souza, "Single Instruction Fetch Does Not Inhibit Instruction-Level Parallelism", In: Workshop on Exploring the Trace Space for Dynamic Optimization Techniques – in conjunction with the International Conference on Supercomputing, SC2003, San Francisco – California, p. 13–21, 2003.
[12] De Souza, Alberto Ferreira; LOUREIRO JÚNIOR, Aminthas (Org.) ; CARRARETO, Geraldo (Org.) ; FONSECA, Marcelo Saba (Org.) ; CUNHA, Oswaldo Paiva Modenesi Martins da (Org.) ; MONTEIRO, Rogério (Org.) . UFES: Planejamento Estratégico 2005-2010. Vitória – ES: Editora Universidade Federal do Espírito Santo, 2005. v. 1. 54p.
[13] SIMÕES, Sergio Nery ; SOUZA, Sotério Ferreira de ; MUNIZ, Leonardo ; FARDIM JÚNIOR, Dijalma ; De Souza, Alberto Ferreira ; REIS JÚNIOR, Neyval Costa ; VALLI, A. M. P. ; CATABRIGA, Lucia . Instalação e Configuração de Clusters de Estações de Trabalho: Experiência do Laboratório de Computação de Alto Desempenho do Departamento de Informática da UFES. Anais do IV Workshop em Sistemas Computacionais de Alto Desempenho. Porto Alegre: Sociedade Brasileira de Computação, 2003. p. 156-159.
[14] F. T. Pedroni, F. L. L. Almeida e A. F. De Souza, "Implementação de uma Versão Power Aware do Simulador DTSVLIW", aceito para publicação nos anais do V Workshop em Sistemas Computacionais de Alto Desempenho – WSCAD'2004, Foz do Iguaçu – RS, 2004.
[15] M. Gowan, L. Biro, and D. Jackson, "Power considerations in the design of the Alpha 21264 microprocessor", In Proceedings of ACM/IEEE Design Automation Conference, p. 726-731, June 1998.
[16] D. Brooks, V. Tiwari, and M. Martonosi, "Wattch: A framework for architectural-level power analysis and optmizations", In Proceedings of the 27th Annual International Symposium on Computer Architecture, p. 83-94, June 2000.
[17] Y. Zhang, D. Parikh, K. Sankaranarayanan, K. Skadron, and M. Stan, "Hotleakage: A temperature-aware model of subthreshold and gate leakage for architects", Technical Report CS-2003-05, University of Virginia Department of Computer Science, March 2003.
[18] A. J. KleinOsowski and D. J. Lilja, "MinneSPEC: A New SPEC Benchmark Workload for Simulation-Based Computer Architecture Research", Computer Architecture Letters, Volume 1, June, 2002.
[19] F. L. Almeida e A. F. De Souza, "O Efeito da Latência no Desempenho da Arquitetura DTSVLIW", In: Anais do IV Workshop em Sistemas Computacionais de Alto Desempenho, São Paulo – SP, p. 64-71, 2003.
[20] N. S. Kim, T. Austin, D. Blaauw, T. Mudge, K. Flautner, J. S. Hu, M. J. Irwin, M. Kandemir, V. Narayanan, "Leakege Current: Moore's Law Meets Static Power", IEEE Computer, Vol. 36, No. 12, December 2003.
[21] P. Avouris, "Supertubes", IEEE Spectrum, Vol. 41, No. 8 (INT), p. 34-39, August 2004.
[22] F. L. Almeida e A. F. De Souza, "Uma Arquitetura DTSVLIW com Múltiplos Contextos de Execução", aceito para publicação nos anais do V Workshop em Sistemas Computacionais de Alto Desempenho – WSCAD'2004, Foz do Iguaçu – RS, 2004.
[23] R. Thekkath, S. J. Eggers, "The Effectiveness of Multiple Hardware Contexts", In Proceedings of the Sixth International Conference on Architectural Support for Programming Languages and Operating Systems, p. 328-337. ACM Press, October 1994.
[24] D. M. Tullsen, S. J. Eggers, and H. M. Levy, "Simultaneous multithreading: Maximizing on-chip parallelism", Proceedings of the 22nd Annual International Symposium on Computer Architecture, p. 392-403, June 22-24, 1995.
[25] S. Ebenholtz, "Oculomotor systems and perception", Cambridge: Cambridge University Press, 2001.
[26] K. S. Komati, "Controle dos Movimentos de Vergência e de Perseguição Suave de Alvos em um Sistema de Visão Binocular Usando Redes Neurais Sem Peso", Dissertação de Mestrado, Programa de Pós-Graduação em Informática – UFES, Fevereiro de 2002.
[27] K. S. Komati and A. F. De Souza, "Vergence Control in a Binocular Vision System using Weightless Neural Networks", In: Proceedings of the 4th International Symposium on Robotics and Automation, Los Alamitos: IEEE, 2002.
[28] K. S. Komati and A. F. De Souza, "Using Weightless Neural Networks for Vergence Control in an Artificial Vision System", Journal Of Applied Bionics And Biomechanics, Auckland, New Zealand, v. 1, n. 1, p. 21-32, 2003.
[29] A. F. De Souza e N. C. Reis Júnior, "Sistema Automático de Medição de Volumes Baseado em Visão Artificial Binocular e Redes Neurais Sem Peso", Projeto FACITEC, 2003.
[30] E. Kandel, J. H. Schwartz, T. M. Jessel, "Principles of Neural Science. 4th Ed.", Prentice-Hall International, Inc., 2000.
[31] D. Fardim Júnior, K. S. Komati, A. F. De Souza, "Arquitetura do Sistema Visual Humano: Uma Abordagem Computacional", In: Lucia Catabriga; Rober Marcone Rosi; Edilson Luiz do Nascimento (Org.). III Escola Regional de Informática RJ/ES, p. 95-126, 2003.
[32] R. B. Tootell, M. S. Silverman, E. Switkes, R. L. De Valois, "Deoxyglucose analysis of retinotopic organization in primate striate cortex", Science, 218:902-904, Nov 26, 1982.
[33] W. Meira Jr.; T. J. LeBlanc . Waiting Time Analysis and Performance Visualization in Carnival. Proceedings of ACM SIGMETRICS Symposium on Parallel and Distributed Tools, 1996, Philadelphia. Anais do Proceedings of ACM SIGMETRICS Symposium on Parallel and Distributed Tools, 1996. p. 1-10.
[34] A. F. De Souza e C. L. Amorim, "Distributed Global Clock for Clusters of Computers", Patente Internacional US7240230 B2, 2003.
[35] A. F. De Souza e C. L. Amorim, "Relógio Global Distribuído para Clusters de Computadores", Patente Nacional PI0300100-8. 2003.
[36] J. L. Hennessy, D. A. Patterson, "Computer Architecture: A Quantitative Approach, Fourth Edition", Morgan Kaufmann Publishers, Inc., 2007.
[37] K. Asanovic, R. Bodik, B. C. Catanzaro, J. J. Gebis, P. Husbands, K. Keutzer, D. A. Patterson, W. L. Plishker, J. Shalf, S. W. Williams, K. A. Yelick, "The Landscape of Parallel Computing Research: A View from Berkeley", Technical Report No. UCB/EECS-2006-183, Department of Electrical Engineering and Computer Sciences, University of California at Berkeley, 2006.
[38] P. Rounce, A. F. De Souza, "The mDTSVLIW: a Multi-Threaded Trace-based VLIW Architecture", Proceedings of the 18th SBC/IEEE International Symposium on Computer Architecture and High Performance Computing, Los Alamitos – CA – USA: IEEE Computer Society, pp. 63-72, 2006.
[39] P. Rounce, A. F. De Souza, "Dynamic Instruction Scheduling in a Trace-Based Multi-Threaded Architecture", aceito para publicação no International Journal of Parallel Programming, 2007.
[40] F. L. Almeida, A. F. De Souza, E. S. T. Fernandes, "Escalonamento Dinâmico de Caminhos de Execução em Blocos de Instruções Dataflow", Dissertação de Mestrado, Programa de Pós-Graduação em Informática – UFES, 2007.
[41] K Sankaralingam, R. Nagarajan, H. Liu, C. Kim, J. Huh, D. Burger, S. W. Keckler, C. R. Moore, "Exploiting ILP, TLP, and DLP with the Polymorphous TRIPS Architecture", Proceedings of the 30th Annual International Symposium on Computer Architecture, pp. 422-433, 2003.
[42] D. Burger, S. W. Keckler, K. S. McKinley, M. Dahlin, L. K. John, C. Lin, C. R. Moore, J. Burrill, R. G. McDonald, W. Yoder, "Scaling to the End of Silicon with EDGE Architectures", IEEE Computer, Vol. 37, No. 7, pp. 44-55, July 2004.
[43] Pedroni, Felipe Thomaz ; De Souza, Alberto F. ; BADUE, Claudine . The Dynamic Block Remapping Cache. Proceedings of the 22nd International Symposium on Computer Architecture and High Performance Computing – SBAC-PAD'2010. Los Alamitos, USA: IEEE Computer Society, 2010. v. 1. p. 111-118.
[44] H. Aboud, N. C. Reis Jr., A. F. De Souza, A. B. Silveira, J. M. Santos, "Modelagem Numérica da Dispersão Atmosférica de Poluentes em Regiões Urbanas de Relevo Complexo Utilizando Processamento Paralelo e Distribuído", Proceedings of the XXVI Iberian Latin-American Congress on Computational Methods in Engineering – CILAMCE'2005, 2005.
[45] J. P. Angeli, A. M. P. Valli, N. C. Reis Jr., A. F. De Souza, "Finite Difference Simulations of the Navier-Stokes Equations using Parallel Distributed Computing", Proceedings of the 15th SBC/IEEE Symposium on Computer Architecture and High Performance Computing, Los Alamitos – CA – USA: IEEE Computer Society, pp. 149-156, 2003.
[46] J. P. Angeli, N. C. Reis Jr., A. F. De Souza, A. M. P. Valli, "Algoritmos de Mecânica dos Fluidos Computacional Utilizando Estratégias de Solução para Utilização Eficiente da Memória Cache de Microprocessadores", Proceedings of the XXVI Iberian Latin-American Congress on Computational Methods in Engineering – CILAMCE'2005, 2005.
[47] E. L. Nascimento, N. C. Reis Jr., A. F. De Souza, "Comparação de Técnicas de Paralelização Aplicadas a Métodos Computacionais para Problemas de Fenômenos de Transporte", Encontro Nacional de Ciência Térmicas – ENCIT'2002, 2002.
[48] E. L. Nascimento, N. C. Reis Jr., A. F. De Souza, J. M. Santos, "3D Navier-Stokes solution algorithm for Clusters of Workstations", Proceedings of the XXIV Iberian Latin-American Congress on Computational Methods in Engineering, 2003.
[49] E. L. Nascimento, N. C. Reis Jr., A. F. De Souza, J. M. Santos, "Parallel Performance of a 3D Navier-Stokes Solution Algorithm for Clusters of Workstations", Revista Engenharia Ciência Tecnologia, Vitória – ES, Vol. 7, No. 1, pp. 47-56, 2004.
[50] E. L. Nascimento, N. C. Reis Jr., A. F. De Souza, J. M. Santos, F. Curbani, "Simulação das Grandes Escalas Turbulentas de um Escoamento e Dispersão de Poluentes ao Redor de um Obstáculo Utilizando Processamento Paralelo", Proceedings of XXVI Iberian Latin-American Congress on Computational Methods in Engineering – CILAMCE'2005, 2005.
[51] N. C. Reis Jr., A. F. De Souza, A. M. P. Valli, J. P. Angeli, "Numerical Simulations of the Navier-Stokes Equations using Clusters of workstations" Proceedings of the XXIV Iberian Latin-American Congress on Computational Methods in Engineering – CILAMCE'2003, 2003.
[52] S. N. Simões, A. F. De Souza, N. C. Reis Jr., E. L. Nascimento, "Uma comparação entre um algoritmo síncrono e um parcialmente assíncrono para solução das equações de Navier-Stokes", Proceedings of the XXVI Iberian Latin-American Congress on Computational Methods in Engineering – CILAMCE'2005, 2005.
[53] A. F. De Souza, S. F. Souza, C. L. Amorim, P. Lima and P. Rounce, "Hardware Supported Synchronization Primitives for Clusters", submetido para The 2008 International Conference on Parallel and Distributed Processing Techniques and Applications 2008, Las Vegas, Nevada, USA.
[54] "Lei de Moore": A capacidade da indústria de dobrar a cada dois anos (aproximadamente) o número de dispositivos (transistores) que podem ser colocados em um circuito integrado.
[55] G. E. Moore, "Cramming more components onto integrated circuits", Electronics, Vol. 38, No. 8, pp. 114-117, 1965.
[56] J. M. Tendler, J. S. Dodson, J. S. Fields Jr., H. Le, B. Sinharoy, "POWER4 System Microarchitecture", IBM Journal of Research and Development, Vol. 46, No. 1, pp. 5-26, 2002.
[57] P. Kongetira, K. Aingaran, K. Olukotun, "Niagara: A 32-Way Multithreaded Sparc Processor", IEEE Micro, Vol. 25, No. 2, pp. 21-29, 2005.
[58] "We are dedicating all of our future product development to multi-core designs. … This is a sea change in computing." Paul Otellini, Presidente da Intel (2005).
[59] S. Borkar, "Design challenges of technology scaling", IEEE Micro, Vol. 19, No. 4, pp. 23–29, 1999.
[60] M. J. Irwin, J. P. Shen, "Revitalizing Computer Architecture Research", Third in a Series of CRA Conferences on Grand Research Challenges in Computer Science and Engineering, December 4-7, 2005, Computing Research Association (CRA), 2007.
[61] J. L. Manferdelli, "The Many-Core Inflection Point for Mass Market Computer Systems", CTWatch (Cyberinfrastructure Technology Watch) Quartely, Vol. 3, No. 1, pp. 11-17, 2007.
[62] J. McCalpin, C. Moore, P. Hester, "The Role of Multi-core Processors in the Evolution of General-Purpose Computing", CTWatch (Cyberinfrastructure Technology Watch) Quartely, Vol. 3, No. 1, pp. 18-30, 2007.
[63] J. Dongarra, D. Gannon, G. Fox, K. Kennedy, "The Impact of Multi-core on Computational Science Software", CTWatch (Cyberinfrastructure Technology Watch) Quartely, Vol. 3, No. 1, pp. 3-10, 2007.
[64] W. A. Wulf, S. A. McKee, "Hitting the Memory Wall: Implications of the Obvious", Computer Architecture News, vol. 23, no. 1, Mar. 1995, pp. 20–24.
[65] E. S. T. Fernandes, V. C. Barbosa, F. Ramos, "Instruction Usage and the Memory Gap Problem", Proceedings of the 14th SBC/IEEE Symposium on Computer Architecture and High Performance Computing, Los Alamitos – CA – USA: IEEE Computer Society, pp. 169-175, 2002.
[66] ITRS, "The International Technology Roadmap for Semiconductors, 2009 Edition: Executive Summary", International Technology Roadmap for Semiconductors, www.itrs.net, 2010.
[67] P. Rounce, A. F. De Souza, "Dynamic Instruction Scheduling in a Trace-Based Multi-Threaded Architecture", International Journal of Parallel Programming, v. 36, p. 184-205, 2008.
[68] F. L. Almeida, A. F. De Souza, E. S. T. Fernandes, "DTSD: Uma Arquitetura com Mecanismo Híbrido de Execução", IX Workshop em Sistemas Computacionais de Alto Desempenho – WSCAD-SSC'2008, pp. 45-52, 2008.
[69] J. O. Neto, A. F. De Souza, "Desempenho SPEC2000 Preliminar da Arquitetura Dynamically Trace Scheduling Dataflow", IX Workshop em Sistemas Computacionais de Alto Desempenho – WSCAD-SSC'2009, 2009.
[70] J. Nickolls, I. Buck, M. Garland, K. Skadron. Scalable Parallel Programming with CUDA. In: ACM Queue, Vol. 6, No. 2, 40-53, March/April 2008.
[71] A. C. Barbosa, L. Catabriga, A. F. De Souza, A. M. P. Valli, "Análise do processamento paralelo em Clusters multi-core na simulação de escoamento míscivel implementado pelo método dos elementos finitos", Anais do X Workshop em Sistemas Computacionais de Alto Desempenho – WSCAD-SCC'2009, pp. 87-94, 2009.
[72] A. C. Barbosa, L. Catabriga, A. M. P. Valli, A. F. De Souza, "Evaluation of Parallel Simulations on Multi-core clusters of miscible displacement applications", Proceedings of the XXX Iberian Latin American Congress on Computational Methods in Engineering, Vol. 1, pp. 1-15, 2009.
[73] L. Veronese, L. M. Lima, A. F. De Souza, L. Catabriga, "Evaluation of Two Parallel Finite Element Implementations of the Time-Dependent Advection Diffusion Problem: CUDA versus MPI", 23rd International Conference for High Performance Computing, Networking, Storage and Analysis – SC'2010, 2010.
[74] C. A. Carvalho, L. P. Veronese, H. Oliveira, A. F. De Souza, "Implementation of a Biologically Inspired Stereoscopic Vision Model in C+CUDA", Proceedings of the NVIDIA Research Summit, San Jose, California, 2009.
[75] L. P. Veronese, A. F. De Souza, C. Badue, E. Oliveira, P. M. Ciarelli, "Implementation in C+CUDA of Multi-Label Text Categorizers", Proceedings of the NVIDIA Research Summit, San Jose, California, 2009.
[76] L. P. Veronese, A. F. De Souza, C. Badue, E. Oliveira, P. M. Ciarelli, "Implementação Paralela em C+CUDA de um Categorizador Multi-Rótulo de Texto Baseado no Algoritmo k-NN", Anais do X Workshop em Sistemas Computacionais de Alto Desempenho – WSCAD-SSC'2009, pp. 145-152, 2009.
[77] IBGE. Classificação Nacional de Atividades Econômicas – Fiscal (CNAE-Fiscal). Instituto Brasileiro de Geografia e Estatística (IBGE), Rio de Janeiro, 2003.
[78] N. Nedjah, L. M. Mourelle, J. Kacprzyk, F. M. G. França, A. F. De Souza, "Intelligent Text Categorization and Clustering". Springer, 2009. 120 p.
[79] A. F. De Souza, F. T. Pedroni, E. Oliveira, P. M. Ciarelli, W. H. Favoreto, L. Veronese, C. Badue, "Automated multi-label text categorization with VG-RAM weightless neural networks", Neurocomputing (Amsterdam), Vol. 72, pp. 2209-2217, 2009.
[80] A. F. De Souza, B. Z. Melotti, C. Badue, "Multi-Label Text Categorization with a Data Correlated VG-RAM Weightless Neural Network", International Journal of Computer Information Systems and Industrial Management Applications, Vol. 1, pp. 155-169, 2009.
[81] A. F. De Souza, F. T. Pedroni, E. Oliveira, P. M. Ciarelli, W. F. Henrique, L. Veronese, "Automated Free Text Classification of Economic Activities using VG-RAM Weightless Neural Networks", Proceedings of the 7th International Conference on Intelligent Systems Design and Applications, Los Alamitos – USA : IEEE Computer Society, pp. 782-787, 2007.
[82] E. Oliveira, P. M. Ciarelli, W. F. Henrique, L. Veronese, F. T. Pedroni, A. F. De Souza, "Intelligent Classification of Economic Activities from Free Text Descriptions", Anais do V Workshop em Tecnologia da Informação e da Linguagem Humana, pp. 1635-1639, 2007.
[83] C. Badue, F. Pedroni, A. F. De Souza, "Multi-label Text Categorization Using VG-RAM Weightless Neural Networks", Proceedings of the 10th Brazilian Symposium on Neural Networks, Los Alamitos – USA : IEEE Computer Society, pp. 105-110, 2008.
[84] A. F. De Souza, C. Badue, B. Z. Melotti, F. T. Pedroni, F. L. L. Almeida, "Improving VG-RAM WNN Multi-label Text Categorization via Label Correlation", Proceedings of the Eighth International Conference on Intelligent Systems Design and Applications, Los Alamitos – USA : IEEE Computer Society, pp. 437-442, 2008.
[85] E. Oliveira, P. M. Ciarelli, C. Badue, A. F. De Souza, "A Comparison between a KNN Based Approach and a PNN Algorithm for a Multi-label Classification Problem", Proceedings of the Eighth International Conference on Intelligent Systems Design and Applications, Los Alamitos – USA : IEEE Computer Society, pp. 628-633, 2008.
[86] E. Oliveira, P. M. Ciarelli, A. F. De Souza, C. Badue, "Using a Probabilistic Neural Network for a Large Multi-label Problem", Proceedings of the 10th Brazilian Symposium on Neural Networks. Los Alamitos – USA : IEEE Computer Society, pp. 195-200, 2008.
[87] I. Aleksander, "From WISARD to MAGNUS: a Family of Weightless Virtual Neural Machines – Chapter of 'RAM-Based Neural Networks'", pages 18-30, World Scientific, 1998.
[88] A. F. De Souza, C. Badue, F. Pedroni, E. Oliveira, S. S. Dias, H. Oliveira, S. F. Souza, "Face Recognition with VG-RAM Weightless Neural Networks", Proceedings of the 18th International Conference on Artificial Neural Networks (ICANN'08), pp. 951-960, 2008.
[89] A. F. De Souza, C. Badue, F. T. Pedroni, S. S. Dias, H. Oliveira, S. F. Souza, "VG-RAM Weightless Neural Networks for Face Recognition – Chapter of 'Face Recognition'", InTech Education and Publishing, Intechweb, pp. 171-186, 2010.
[90] H. M. Markowitz, "The Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel", 1990, Disponível em: <http://nobelprize.org/nobel_prizes/economics/laureates/1990/>.
[91] F. D. Freitas, A. F. De Souza, A. R. Almeida, "Prediction-Based Portfolio Optimization Model Using Neural Networks", Neurocomputing (Amsterdam), Vol. 72, pp. 2155-2170, 2009.
[92] F. D. Freitas, P. M. Ciarelli, A. F. De Souza, "Previsão da Arrecadação Federal com Redes Neurais", Anais do IX Congresso Brasileiro de Redes Neurais, 2009.
[93] A. F. De Souza, F. Machado, "Visão artificial na medição e controle da produção e fluxo de materiais – do manuseio de granel até as linhas de produção", Anais do XXVI Seminário de Logística, 2007.
[94] J. L. Moraes, A. F. De Souza and C. Badue, "Facial Access Control Based on VG-RAM Weightless Neural Networks," in Proceedings of the International Conference on Artificial Intelligence, 2011.
[95] M. Berger, A. Forechi, A. F. De Souza, J. O. Neto, L. P. Veronese, V. N. Neves and C. Badue, "Traffic Sign Recognition with VG-RAM Weightless Neural Networks," in Proceedings of the International Conference on Intelligent Systems Design and Applications, pp. 315-319, 2012.
[96] M. Berger, A. Forechi, A. F. De Souza, J. O. Neto, L. P. Veronese, V. N. Neves, E. De Aguiar and C. Badue, "Traffic Sign Recognition with WiSARD and VG-RAM Weightless Neural Networks," Journal of Network and Innovative Computing, v.1, pp.87-98, 2013.
[97] J. Stallkamp, M. Schlipsing, J. Salmen and C. Igel, "The German Traffic Sign Recognition Benchmark: a Multi-Class Classification Competition," in Proceedings of the International Joint Conference on Neural Networks, pp. 1453-1460, 2011.
[98] J. Stallkamp, M. Schlipsing, J. Salmen and C. Igel, "Man vs. Computer: Benchmarking Machine Learning Algorithms for Traffic Sign Recognition," Neural Networks, v. 32, pp. 323-332, 2012.
[99] L. P. Veronese, L. J. L. Junior, F. W. Mutz, J. O. Neto, V. B. Azevedo, M. Berger, A. F. De Souza and C. Badue, "Stereo Matching with VG-RAM Weightless Neural Networks," in Proceedings of the International Conference on Intelligent Systems Design and Applications, pp.309-314, 2012.
[100] D. S. R. Scharstein, "A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms," International Journal of Computer Vision, vol. 47, p. 7–42, 2002.
[101] A. F. De Souza, C. Fontana, F. W. Mutz, T. A. Oliveira, M. Berger, A. Forechi, J. O. Neto, E. De Aguiar and C. Badue, "Traffic Sign Detection with VG-RAM Weightless Neural Networks," in Proceedings of the International Joint Conference on Neural Networks, pp. 1-9, 2013.
[102] S. Houben, J. Stallkamp, J. Salmen, M. Schlipsing and C. Igel, "Detection of Traffic Signs in Real-World Images: the German Traffic Sign Detection Benchmark," in Proceedings of the International Joint Conference on Neural Networks, 2013, pp. 1-8.
[103] V. B. Azevedo, A. F. De Souza, L. P. Veronese, C. Badue and M. Berger, "Real-time Road Surface Mapping Using Stereo Matching, V-Disparity and Machine Learning," in Proceedings of International Joint Conference on Neural Networks (IJCNN'2013), Dallas, Texas, pp. 1-8, 2013.
[104] Rômulo Ramos Radaelli, Claudine Badue, Michael André Gonçalves, Thiago Oliveira-Santos, Alberto F. De Souza, "A Motion Planner for Car-Like Robots Based on Rapidly-Exploring Random Trees", In: Ibero-American Conference on Artificial Intelligence (IBERAMIA 2014), pp. 469-480, 2014.
[105] Lyrio, Lauro J. ; Oliveira-Santos, Thiago ; Badue, Claudine ; De Souza, Alberto Ferreira . Image-based mapping, global localization and position tracking using VG-RAM weightless neural networks. In: 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle. pp. 3603-3610, 2015.
[106] F. D. d. Freitas, C. T. d. Brito Neto and A. F. De Souza, "Avaliação do risco da arrecadação federal por meio de macrocarteiras de tributos," Revista de Administração Pública, vol. 46, no. 1, pp. 93-123, 2012.
[107] A. F. De Souza, F. D. Freitas and A. G. C. d. Coelho, "Fast learning and predicting of stock returns with virtual generalized random access memory weightless neural networks," Concurrency and Computation, vol. 24, no. 8, pp. 921-933, 2012.
[108] M. Peltz, "Inside the machine: a journey into the world of high-frequency trading," Institutional Investor, vol. 45, no. 5, pp. 42-48, 90-93, June 2010.
[109] A. F. De Souza, L. Veronese, L. M. Lima and L. Catabriga, "Evaluation of Two Parallel Finite Element Implementations of the Time-Dependent Advection Diffusion Problem: GPU versus Cluster Considering Time and Energy Consumption," in High Performance Computing for Computational Science – VECPAR'2012, Kobe, pp. 149-162, 2012.
[110] L. Veronese, L. J. Lyrio Jr, J. d. Oliveira Neto, A. Forechi, C. Badue and A. F. De Souza, "Parallel Implementations of the CSBP Stereo Vision Algorithm," in Anais do XII Simpósio em Sistemas Computacionais, Los Alamitos, 2011.
[111] J. Nickolls, I. Buck, M. Garland and K. Skadron, "Scalable Parallel Programming with CUDA," ACM Queue, vol. 6, p. 4–53, 2008.
[112] NVIDIA, NVIDIA CUDA 3.0 – Programming Guide, NVIDIA Corporation, 2010.
[113] M. Buehler, K. Iagnemma and S. Singh, The DARPA Urban Challenge: Autonomous Vehicles in City Traffic, Berlin: Springer-Verlag, 2009.
[114] Mutz, Filipe ; Veronese, Lucas P. ; Oliveira-Santos, Thiago ; De Aguiar, Edilson ; Auat Cheein, Fernando A. ; De Souza, Alberto F. Large-scale mapping in complex field scenarios using an autonomous car. Expert Systems with Applications, v. 46, p. 439-462, 2016.
[115] Veronese, L. P. ; Aguiar, E. ; Nascimento, R. C. ; Guivant, J. ; Cheein, F. A. A. ; De Souza, A. F. ; Oliveira-Santos, Thiago . Re-Emission and Satellite Aerial Maps Applied to Vehicle Localization on Urban Environments. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, pp. 4285-4290, 2015.
[116] Veronese, Lucas De Paula ; Auat Cheein, Fernando ; Bastos-Filho, Teodiano ; Ferreira De Souza, Alberto ; De Aguiar, Edilson . A Computational Geometry Approach for Localization and Tracking in GPS-denied Environments. Journal of Field Robotics, v. 1, p. n/a-n/a, 2015.
[117] Lyrio Jr., Lauro J. ; Oliveira-Santos, Thiago ; Forechi, Avelino ; Veronese, L. P. ; BADUE, Claudine ; DE SOUZA, A. F. ; De Souza, Alberto Ferreira . Image-Based Global Localization Using VG-RAM Weightless Neural Networks. In: International Joint Conference on Neural Networks (IJCNN 2014), Beijin, pp. 1-8, 2014.
[118] Castillo, Javier ; Muller, Sandra ; Caicedo, Eduardo ; De Souza, Alberto Ferreira ; Bastos, Teodiano . Proposal of a Brain Computer Interface to command an autonomous car. In: 5th IEEE Biosignals and Biorobotics conference (BRC 2014), Salvador, pp. 1-8, 2014.
[119] Aguiar, E. ; Forechi, Avelino ; Veronese, L. P. ; Berger, M. ; De Souza, Alberto Ferreira ; Badue, Claudine ; Oliveira-Santos, Thiago . Compressing VG-RAM WNN Memory for Lightweight Applications. In: International Joint Conference on Neural Networks (IJCNN 2014), Beijin, 2014.
[120] De Souza, A. F.; Forechi, Avelino ; Mutz, F. W. ; Berger, M. ; Oliveira-Santos, Thiago ; Badue, Claudine . Programming a VG-RAM Based Neural Network Computer. In: International Joint Conference on Neural Networks (IJCNN 2014), Beijin, 2014.
[121] Freitas, Fabio Daros ; Freitas, Christian Daros ; De Souza, Alberto Ferreira . Intelligent trading architecture. Concurrency and Computation, v. 28, no. 3, pp. 929-943, 2015.